

摘要:当用户行为、活动记录、检测数据等业务表进入千万级甚至亿级后,单纯依赖 SQL 优化很快会碰到天花板。本文结合真实业务场景,系统梳理 MySQL 分区、分库分表、冗余全量表、冗余关系表,以及 ClickHouse 在海量数据分析场景下的应用方式,并重点讨论 ClickHouse 更新数据的几种方案:ALTER UPDATE、Incremental Log、ReplacingMergeTree、AggregatingMergeTree 和 FINAL 查询。适合正在处理海量用户数据、慢查询、分库分表和 OLAP 架构选型的后端开发者阅读。
写在前面:SQL 优化不是无限续命
最近一段时间,业务里的用户相关数据增长很快。每做一次活动,就会产生几百万到上千万条用户行为、检测结果或业务流水。刚开始还能靠 SQL 优化解决,比如补索引、改查询条件、减少回表、拆复杂 join、控制分页深度。
这些手段当然有用。问题是,数据量继续增长以后,慢查询不再只是某一条 SQL 写得不够好,而是整个数据模型已经扛不住当前访问模式了。
典型表现有几个:
单表数据进入千万级后,索引体积明显变大。
活动结束后批量写入高峰把主库压得很紧。
查询条件越来越多,不可能每个组合都建索引。
按用户查、按活动查、按时间查、按项目查,访问路径互相冲突。
报表统计需要扫大量数据,OLTP 库被拖慢。
业务还要求“准实时”,不能每天离线跑一次就完事。
到这个阶段,继续只盯着单条 SQL,收益会越来越低。更现实的做法是:把问题拆开。
OLTP 主链路继续用 MySQL 保证事务、写入和核心查询;海量分析、聚合统计、跨维度查询,逐步交给 ClickHouse 这类 OLAP 数据库。中间用分库分表、冗余表、数据同步和最终一致性把两边连接起来。
一、MySQL 面对海量数据时的两条路
关系型数据库里,常见扩展方式有两类:
第一类是分区。还是一张逻辑表,只是底层按规则切成多个分区。
第二类是分库分表。把数据拆到多个物理库、物理表,应用或中间件负责路由。
这两种方案经常被放在一起讨论,但它们解决的问题不完全一样。
二、MySQL 分区:单库里的“表内拆分”
1. 分区的基本原理
MySQL 分区表对业务层表现为一张表。底层会根据分区规则,把数据放到不同分区里。查询时,如果条件能命中分区裁剪,MySQL 可以少扫一部分数据。
例如按日期分区:
CREATE TABLE user_event (
id BIGINT NOT NULL,
user_id BIGINT NOT NULL,
event_type VARCHAR(32) NOT NULL,
event_time DATETIME NOT NULL,
PRIMARY KEY (id, event_time)
)
PARTITION BY RANGE (TO_DAYS(event_time)) (
PARTITION p20260501 VALUES LESS THAN (TO_DAYS('2026-05-02')),
PARTITION p20260502 VALUES LESS THAN (TO_DAYS('2026-05-03')),
PARTITION pmax VALUES LESS THAN MAXVALUE
);查询时如果带上 event_time 范围:
SELECT *
FROM user_event
WHERE event_time >= '2026-05-01'
AND event_time < '2026-05-02'
AND user_id = 10001;数据库可以只访问对应日期分区,而不是扫全部数据。
2. 分区的优点
分区最大的优点是透明。对业务代码来说,它还是一张表。SQL 不需要改成访问 user_event_001、user_event_002。如果查询条件里有分区键,还能利用分区裁剪减少扫描量。
另一个优点是运维动作方便。比如按月归档历史数据,可以直接 drop 某个历史分区,比一行行 delete 更干净。
ALTER TABLE user_event DROP PARTITION p202401;3. 分区的缺点
分区不是分布式。它仍然在一个 MySQL 实例里,连接数、CPU、内存、磁盘 IO、网络吞吐都受单机限制。分区能减少部分查询的扫描范围,但不能把并发能力扩展到多台机器。
另外,分区效果强依赖查询条件。如果查询不带分区键,还是可能扫很多分区。分区键选错以后,后续调整成本也不低。
4. 分区适合什么场景
分区更适合:
数据量比较大,但还没有大到必须横向扩展。
查询天然带时间、租户、区域等分区条件。
有明确的历史数据归档需求。
并发压力主要不是数据库单机瓶颈。
如果问题是“单机已经扛不住写入和查询”,分区不是终点。
三、分库分表:互联网业务里的常规解法
分库分表解决的是横向扩展问题。它把数据拆到多个库和多张表里,通过路由规则把请求打到正确的数据节点。
常见中间件形态有两类。
1. Client 模式
Client方式是指分库分表的逻辑都在应用本地进行控制,应用本地会直连多个数据库进行操作,然后本地进行数据的聚合汇总等操作逻辑。Java 项目里常见的是 ShardingSphere-JDBC 这一类方案。
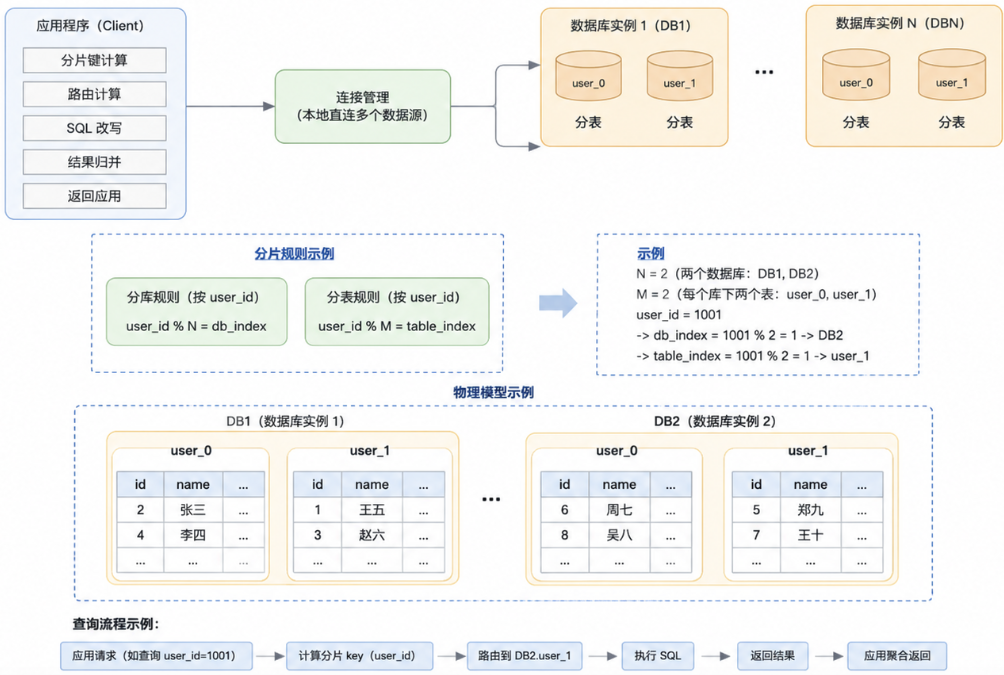
优点:
少一层网络代理,性能损耗相对小。
和 Java 项目集成方便。
应用可以更精细地控制事务、连接池和路由。
缺点:
每个应用都要接入对应 SDK。
多语言系统里复用成本高。
分片规则变更需要关注应用发布。
2. Proxy 模式
Proxy方式是指挥有一个独立的应用,这个应用实现了Mysql的协议,可以对外提供服务。业务方的应用不需要直接连接数据库,而是连接这个Proxy的应用,把这个Proxy就当做一个数据库使用。Proxy会将Sql分发到具体的数据库进行执行,并返回结果。
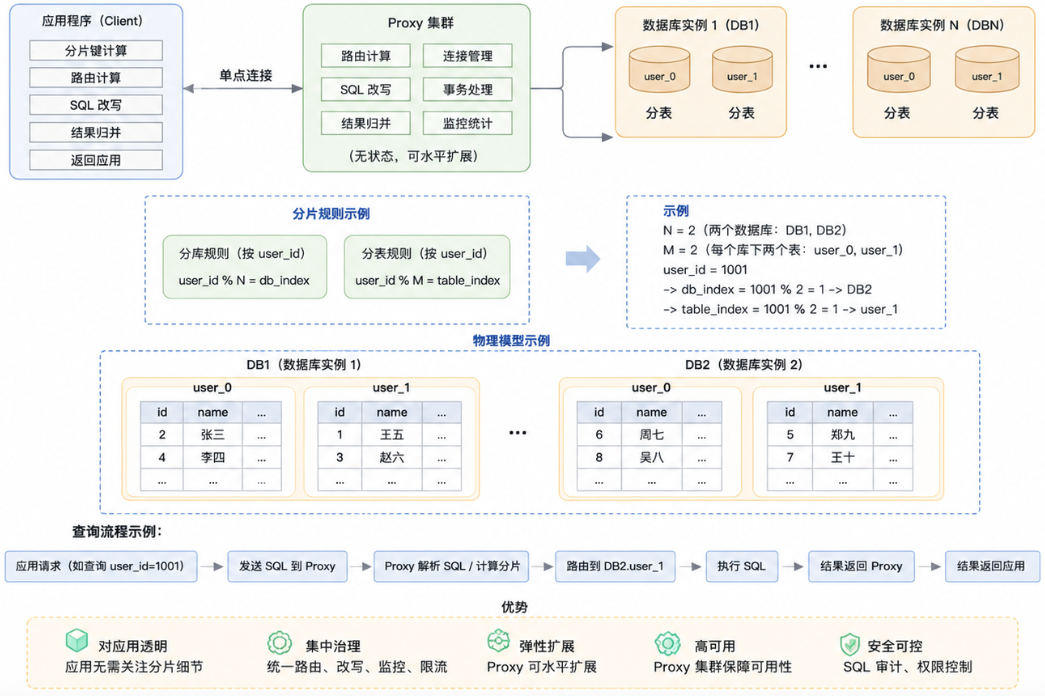
优点:
对应用侵入小。
多语言系统接入统一。
分片规则集中管理。
缺点:
多一层网络转发和代理维护成本。
Proxy 本身要做高可用。
复杂 SQL 的兼容性和性能都要提前验证。
不管是 Client 还是 Proxy,核心步骤都绕不开:SQL 解析、路由、改写、执行、结果归并。也正因为这样,分库分表不是把库表数量一拆就完事。真正难的是后面的查询模型、事务边界、全局 ID、跨分片聚合、扩容迁移和数据一致性。
四、分片键怎么选:决定方案成败的第一步
分库分表里最重要的设计,是分片键,也就是 sharding column。选分片键时,不要先拍脑袋说“用户系统就按 user_id”。更靠谱的方式是把 API 流量拉出来看:
哪些接口访问量最高?
这些接口对应哪些 SQL?
SQL 里稳定出现的查询条件是什么?
写入和查询是否都能带上这个条件?
后续统计是否会大量跨分片?
分片键选得好,大多数请求都能路由到单库单表。分片键选得差,大量请求会变成广播查询,性能会比单表更难看。
这里结合我们的实际业务举例:学生(user表)定期参加体能测试(detect表),每一次体测之后,保留对应检测数据(data表),涉及以下三张核心表:
user:学生信息。detect:体测任务。data:学生体测结果。核心字段如下:
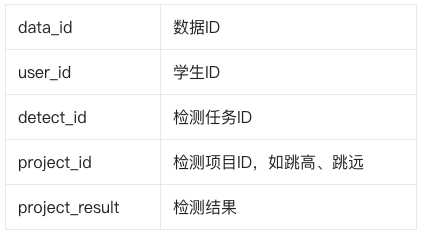
业务中有两类高频查询:
第一类是教师或运营侧查询:统计一次体测任务中所有学生的项目成绩。
SELECT *
FROM data
WHERE detect_id = ?;第二类是学生端查询:查看自己历次体测数据,用来做纵向对比。
SELECT *
FROM data
WHERE user_id = ?
ORDER BY detect_id DESC;如果只按 detect_id 分片,任务统计很舒服,但学生端按 user_id 查询就可能跨所有分片;如果只按 user_id 分片,学生端很舒服,但一次体测任务汇总又要跨很多分片。
这就是分库分表里最常见的矛盾:业务天然有多个访问维度,但单套分片规则只能照顾一个主维度。
五、多访问维度下的冗余表设计
面对多个高频查询维度,通常有两种冗余方案。
1. 冗余全量表
冗余全量表的做法是:为不同查询维度分别维护一套完整数据。例如体测数据分别维护三套表:
data_by_data_id_xx
data_by_detect_id_xx
data_by_user_id_xx每套表都保存完整字段,只是分片键不同。写入一条体测结果时,同时写三份:
按 data_id 写入 data_by_data_id
按 detect_id 写入 data_by_detect_id
按 user_id 写入 data_by_user_id查询时:
详情查询走
data_id。活动统计走
detect_id。学生历史走
user_id。
优点很明显:查询快,路径直,基本都能单分片命中;缺点也明显:存储成本高,写入放大,更新和删除要维护多份数据。
这种方案适合读压力大、查询延迟敏感、存储成本可接受的业务。
2. 冗余关系表
冗余关系表的做法是:主表保存全量数据,其他维度只保存关系索引。例如:
data_by_data_id_xx -- 全量数据
data_detect_relation_xx -- detect_id -> data_id
data_user_relation_xx -- user_id -> data_id按 detect_id 查询时,先查关系表拿到 data_id 列表,再回主表批量查详情。
优点:
存储成本比全量冗余低。
数据变更时维护压力小一些。
关系表可以补充少量常用字段,例如学生姓名、任务名称、项目结果摘要。
缺点:
查询需要二次访问。
回表时可能跨分片。
对缓存、批量查询和结果拼装要求更高。
这种方案适合数据字段多、存储成本敏感、查询延迟要求没那么极限的场景。
3. 两种方案怎么选
可以简单按下面几个问题判断:
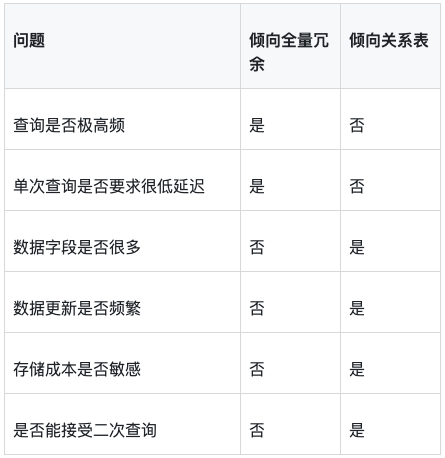
在体测这类业务里,如果一次活动后查询量很高,教师端和学生端都要快速出结果,冗余全量表通常更直接。存储多花一些钱,但换来查询路径简单、系统行为可预测。
六、分库分表落地时容易忽略的问题
1. 全局 ID
分表后不能继续依赖单表自增 ID 作为全局唯一主键。常见方案有:
雪花算法。
数据库号段。
Redis / 发号器。
业务前缀 + 时间 + 序列。
不建议把自增主键暴露成业务全局 ID。迁移、合并、数据同步时会很难受。
2. 跨分片分页
下面这种 SQL 在分库分表后会很贵:
SELECT *
FROM data
WHERE project_id = ?
ORDER BY create_time DESC
LIMIT 10000, 20;如果没有分片键,中间件可能要查多个分片,然后在内存里归并排序。偏移量越大,代价越高。更好的做法是:
查询尽量带分片键。
使用游标翻页。
热门榜单预计算。
报表类查询交给 OLAP 系统。
3. 跨分片 join
跨分片 join 是分库分表的大坑。能避免就避免。常见替代方案:
冗余必要字段。
应用层分两次查询后组装。
使用宽表。
离线或准实时同步到 ClickHouse 做分析。
4. 扩容迁移
分库分表前要想好扩容。如果一开始定 16 张表,后续数据涨到不可控,再改成 64 张表,就涉及历史数据迁移和双写校验。常见策略:
初始表数量适当留余量。
库数量可以逐步增加,表数量尽量稳定。
分片算法支持平滑迁移。
迁移期间做双写、校验和灰度切流。
扩容不是配置改一下这么简单。越早设计,越少补课。
七、为什么还需要 ClickHouse
分库分表能解决 OLTP 扩展问题,但并不适合所有查询。比如:
按活动统计每个项目的平均分、最高分、通过率。
查询某个地区近一年所有学生成绩分布。
按年龄、性别、学校、项目维度做多条件筛选。
不带分片键的运营分析。
大屏、报表、趋势图。
这些查询天然是分析型查询,扫描行数大、聚合多、维度多。如果放在 MySQL 分片集群上做,结果通常是:
SQL 广播到多个分片。
每个分片做聚合。
应用或中间件归并。
MySQL 主库或从库被报表拖慢。
专业的事情最好交给专业的工具。ClickHouse 这类列式 OLAP 数据库,就是为大规模分析查询准备的。ClickHouse 的几个特性很适合用户行为、检测结果、日志、指标这类数据:
1. 列式存储
MySQL 这类 OLTP 数据库通常按行存储。查询一行时很方便,但分析场景经常只关心少数几个列。例如:
SELECT project_id, avg(project_result)
FROM detect_data
WHERE detect_id = 10001
GROUP BY project_id;这个查询只需要 detect_id、project_id、project_result。列式存储可以只读取相关列,减少 IO。
2. 高压缩比
分析数据往往有很多重复值,例如项目 ID、地区 ID、学校 ID、状态枚举。列式存储天然更容易压缩。压缩比高意味着同样磁盘能放更多数据,也意味着扫描时从磁盘读的数据更少。
3. 向量化执行
ClickHouse 擅长批量处理数据,而不是一行行解释执行。对聚合、过滤、排序这类分析操作,性能优势明显。
4. 面向追加写入
很多分析数据都是不断追加的,例如行为日志、检测结果、订单流水。ClickHouse 对批量 insert 很友好。但这里也埋了一个限制:ClickHouse 不喜欢高频随机更新。
八、ClickHouse 更新数据的现实问题
OLAP 数据库通常喜欢不可变数据。现实业务却经常要更新。比如学生体测场景:学生一次跳远成绩不理想,允许重新测试;系统需要保存最终成绩,或者保存多次成绩并取最好一次。这样就会出现更新需求。
ClickHouse 处理更新一般有几类方案。
方案一:ALTER UPDATE
ClickHouse 支持:
ALTER TABLE detect_data
UPDATE project_result = 2.31
WHERE detect_id = 10001
AND user_id = 4
AND project_id = 3;但这不是 MySQL 里那种面向 OLTP 的原地更新。ClickHouse 官方文档把它称为 mutation。它会找到相关数据 part,重写受影响的数据,默认还是异步执行。可以把它理解成:不是“改一行”,而是“重写包含这行的一批数据”。所以它适合低频修正,不适合高频业务更新。
适合场景:
人工修正少量历史数据。
数据清洗后批量改某个字段。
运维性补偿。
不适合场景:
用户每次操作都触发 update。
秒级高频状态变更。
把 ClickHouse 当 MySQL 用。
如果业务里频繁执行 ALTER TABLE ... UPDATE,基本说明模型设计有问题。
方案二:Incremental Log
Incremental Log 的思路是:不直接修改旧数据,而是追加一条抵消记录和一条新记录。
假设原始数据:
UserID PageViews Duration Sign
4324182021466249494 5 146 1现在要把 PageViews 从 5 改成 6,Duration 从 146 改成 185,不去 update 原行,而是追加两行:
UserID PageViews Duration Sign
4324182021466249494 5 146 -1
4324182021466249494 6 185 1查询时用带符号的聚合:
SELECT
sum(Sign) AS sessions,
sum(Sign * PageViews) AS page_views,
sum(Sign * Duration) / sum(Sign) AS avg_duration
FROM user_session_log
WHERE UserID = 4324182021466249494;优点:
写入仍然是 insert,符合 ClickHouse 的使用方式。
不需要高频 mutation。
可以保留变更历史。
缺点:
更新时通常要知道原值,否则无法写出抵消行。
查询 SQL 需要按 Sign 改写。
对
min、max、quantile这类计算不一定自然。写入会放大。
ClickHouse 的 CollapsingMergeTree 可以在后台 merge 时折叠正负记录,降低一部分存储压力。但查询模型仍然要理解 Sign 的存在。适合场景:
以聚合统计为主。
更新次数不算太高。
能接受带符号聚合模型。
业务需要保留变更痕迹。
方案三:ReplacingMergeTree
ReplacingMergeTree 是很多人处理“更新”时会优先考虑的方案。它的核心思路也是 insert,不是 update。建表示例:
CREATE TABLE detect_data_ck
(
data_id UInt64,
user_id UInt64,
detect_id UInt64,
project_id UInt32,
project_result Float64,
version UInt64,
updated_at DateTime
)
ENGINE = ReplacingMergeTree(version)
PARTITION BY toYYYYMM(updated_at)
ORDER BY (detect_id, user_id, project_id);当同一个 (detect_id, user_id, project_id) 有多条数据时,后台 merge 会保留 version 最大的那条。插入原始成绩:
INSERT INTO detect_data_ck
VALUES (1, 4, 10001, 3, 2.21, 1, now());重新测试后插入新成绩:
INSERT INTO detect_data_ck
VALUES (1, 4, 10001, 3, 2.31, 2, now());注意,这里没有 update。它只是插入了一个更高版本。
ReplacingMergeTree 的关键限制
ReplacingMergeTree 的去重发生在后台 merge。这个时间不可控。也就是说,刚插入新版本后,普通查询可能同时读到旧版本和新版本。它适合做最终一致的去重,不天然保证任何时刻都没有重复数据。
如果查询要立刻看到逻辑去重后的结果,可以使用 FINAL:
SELECT *
FROM detect_data_ck FINAL
WHERE detect_id = 10001
AND user_id = 4;但 FINAL 会在查询阶段执行合并逻辑,有额外开销。数据量大、part 多、过滤条件不理想时,性能压力会很明显。所以实践中更推荐:
热点查询尽量通过
ORDER BY设计减少扫描范围。能不用
FINAL就不用。对强一致查询建立物化视图或明细宽表。
用业务版本号保证最终取最新。
对大范围报表,不要在每次查询都依赖
FINAL。
适合场景:
数据允许最终一致。
更新本质上可以表达为新版本写入。
查询能容忍短时间重复,或有额外去重逻辑。
明细表需要保留最新版本。
方案四:AggregatingMergeTree / SimpleAggregateFunction
如果业务查询不是明细,而是聚合结果,可以考虑 AggregatingMergeTree。
例如用户画像表、学生最近一次成绩表、项目统计表,可以把列设计成聚合状态。示意:
CREATE TABLE student_project_summary
(
user_id UInt64,
project_id UInt32,
detect_id UInt64,
result SimpleAggregateFunction(anyLast, Float64),
updated_at SimpleAggregateFunction(max, DateTime)
)
ENGINE = AggregatingMergeTree()
ORDER BY (user_id, project_id, detect_id);这里的思路是:同一聚合键下,后台 merge 时按聚合函数合并状态,例如保留最后一次结果或最大更新时间。
优点:
适合预聚合。
查询报表时扫描数据更少。
更新可以通过 insert 新状态表达。
缺点:
仍然依赖后台 merge,天然是最终一致。
明细查询不适合。
查询和建模都比普通表复杂。
适合场景:
报表统计。
用户画像。
多维指标表。
最新状态摘要表。
方案五:xxxMergeTree + FINAL
FINAL 可以让查询返回前执行表引擎的合并逻辑。例如:
SELECT count()
FROM detect_data_ck FINAL
WHERE detect_id = 10001;它的好处是简单。读者一看也明白:我要最终合并后的结果。
但代价也要看清楚:
查询时需要额外合并。
大范围扫描会很重。
part 数多时更明显。
高频查询里滥用
FINAL会吃掉 ClickHouse 的性能优势。
所以 FINAL 更适合:
小范围明细查询。
管理后台低频查询。
对一致性要求高但并发不大的场景。
过渡阶段兜底。
不建议把所有查询都写成 SELECT ... FINAL。这通常是表设计和数据链路没有做好,最后把成本全扔给查询侧。
九、体测业务的实现架构
结合前面的学生体测场景,最终设计如下:
1. MySQL 负责核心写入和高频点查
MySQL 中保留核心业务表:
user
detect
data_by_detect_id
data_by_user_id
data_by_data_id写入体测结果时:
1. 生成全局 data_id
2. 写入 data_by_data_id
3. 写入 data_by_detect_id
4. 写入 data_by_user_id
5. 记录变更事件到 outbox / MQ教师端按 detect_id 查,学生端按 user_id 查,详情按 data_id 查。每条高频路径都有明确的分片键。
2. ClickHouse 负责统计和跨维度查询
ClickHouse 中保留明细宽表:
CREATE TABLE detect_data_wide
(
data_id UInt64,
user_id UInt64,
user_name String,
school_id UInt64,
grade_id UInt64,
detect_id UInt64,
detect_name String,
project_id UInt32,
project_name String,
project_result Float64,
version UInt64,
event_time DateTime
)
ENGINE = ReplacingMergeTree(version)
PARTITION BY toYYYYMM(event_time)
ORDER BY (detect_id, project_id, school_id, user_id, data_id);为什么 ORDER BY 这样设计?
因为报表侧最常见的是按体测任务、项目、学校、学生过滤和聚合。ClickHouse 的排序键不是 MySQL 里的万能索引,它更像“数据组织方式”。把高频过滤维度放在前面,可以减少扫描范围。
3. 数据同步链路
同步可以有几种方式:
MySQL binlog -> Canal / Debezium -> Kafka -> ClickHouse或者:
业务写 MySQL -> Outbox 表 -> 定时投递 MQ -> ClickHouse 消费对强业务一致性要求高的系统,我更偏向 Outbox。因为它能把“写业务表”和“写待同步事件”放在同一个本地事务里,避免业务成功但消息丢失。
4. 更新策略
学生重新测试时,不在 ClickHouse 上做高频 update,而是写入新版本:
INSERT INTO detect_data_wide
(
data_id,
user_id,
user_name,
school_id,
grade_id,
detect_id,
detect_name,
project_id,
project_name,
project_result,
version,
event_time
)
VALUES
(
900001,
4,
'张三',
100,
7,
10001,
'2026 春季体测',
3,
'跳远',
2.31,
2,
now()
);明细查询如果必须看最新:
SELECT *
FROM detect_data_wide FINAL
WHERE detect_id = 10001
AND user_id = 4
AND project_id = 3;大报表不要长期依赖 FINAL,可以改成预聚合表或物化视图。
十、最终方案总结
回到开头的问题:当用户相关数据不断增长,单纯 SQL 优化已经不够时,应该怎么做?
我的答案是分层治理。
第一层,MySQL 继续承接核心业务写入。对高频 OLTP 查询,通过分库分表和冗余表解决。分片键围绕真实 API 流量选择,不围绕数据库表结构想象。
第二层,对多个高频访问维度,必要时采用冗余全量表。它会带来写入和存储成本,但能换来简单、稳定、低延迟的查询路径。
第三层,把跨维度统计、运营分析、大屏报表、低频复杂查询交给 ClickHouse。不要让 MySQL 分片集群承担所有分析压力。
第四层,ClickHouse 里的更新不要照搬 MySQL 思维。优先用 insert 新版本、ReplacingMergeTree、预聚合表、物化视图和最终一致方案。ALTER UPDATE 用于低频修正,FINAL 用于必要场景兜底,不要成为常规查询标配。
第五层,补齐数据同步和校验。只要有冗余,就一定有一致性问题;只要有异步,就一定有延迟窗口。架构设计要承认这一点,而不是假装没有。
海量数据治理没有一个“万能按钮”。它更像是把不同类型的问题放到合适的位置:MySQL 做交易,ClickHouse 做分析;分库分表做高频路径,OLAP 做复杂统计;同步链路做连接,校验体系做兜底。这样系统才能从“慢 SQL 修修补补”走向真正可扩展的数据架构。
评论区