

摘要:本文全面解析分布式缓存机制,涵盖缓存核心问题(穿透/击穿/雪崩)、Redis集群架构与高可用、缓存与数据库一致性方案、热点缓存处理、分布式锁与缓存结合,以及生产环境踩坑经验与最佳实践。适合需要提升系统性能的Java开发者。
一、为什么需要分布式缓存
1.1 单机缓存的局限
本地缓存(如JVM内存、Guava Cache)在单机环境下效果不错:
// Guava本地缓存
private Cache<String, Product> productCache = CacheBuilder.newBuilder()
.maximumSize(10000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
public Product getProduct(String productId) {
return productCache.get(productId, () -> productDao.getById(productId));
}但在分布式环境下有问题:
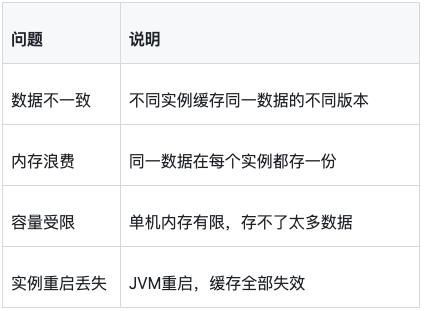
1.2 分布式缓存的优势
分布式缓存(如Redis集群)解决这些问题:
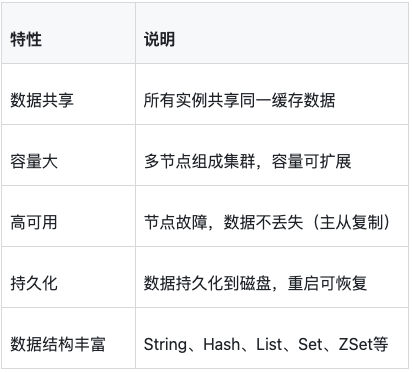
1.3 缓存的应用场景
读多写少场景(缓存效果最好):
商品详情页(商品信息几乎不变)
新闻资讯(发布后不修改)
用户信息(读频繁,修改少)
热点数据场景:
秒杀商品(高并发读取)
热门话题(短时间内大量访问)
排行榜(实时更新)
计数统计场景:
点赞数(Redis原子计数)
浏览量(高并发写入)
库存扣减(Redis预扣减)
二、Redis分布式缓存架构
2.1 Redis数据分布策略
Redis集群如何分布数据到多个节点?
一致性哈希:
1. 将节点映射到哈希环上
2. 数据按key哈希,落在环上某位置
3. 数据归属:环上顺时针方向最近的节点优点:
节点增减只影响相邻节点的数据
数据迁移量小
缺点:
数据分布可能不均匀(热点集中某节点)
2.2 Redis集群模式
要想设计一个高可用的 Redis 服务,一定要从 Redis 的多服务节点来考虑,比如 Redis 的主从复制、哨兵模式、切片集群。
(1)主从复制
主从复制是 Redis 高可用服务的最基础的保证,实现方案就是将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
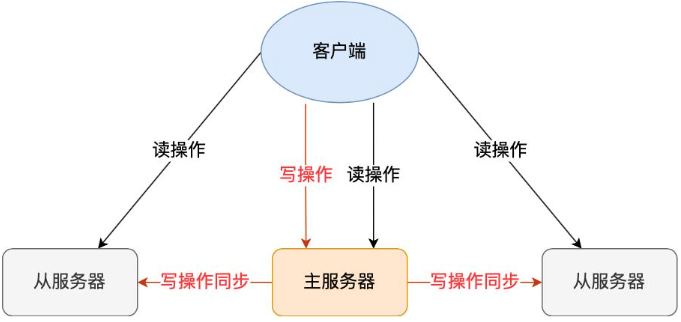
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
主从服务器之间的命令复制是异步进行的。具体来说,在主从服务器命令传播阶段,主服务器收到新的写命令后,会发送给从服务器。但是,主服务器并不会等到从服务器实际执行完命令后,再把结果返回给客户端,而是主服务器自己在本地执行完命令后,就会向客户端返回结果了。如果从服务器还没有执行主服务器同步过来的命令,主从服务器间的数据就不一致了。所以,无法实现强一致性保证(主从数据时时刻刻保持一致),数据不一致是难以避免的。
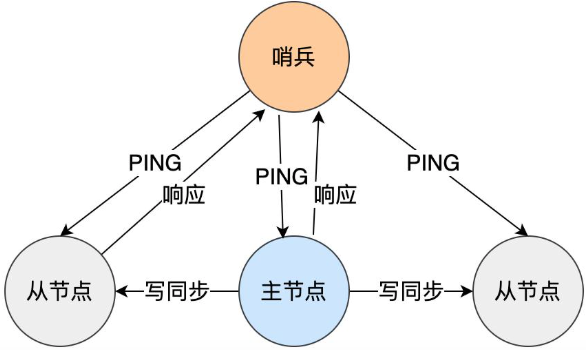
(2)哨兵模式
在使用 Redis 主从服务的时候,会有一个问题,就是当 Redis 的主从服务器出现故障宕机时,需要手动进行恢复。
为了解决这个问题,Redis 增加了哨兵模式(Redis Sentinel),因为哨兵模式做到了可以监控主从服务器,并且提供主从节点故障转移的功能。
(3)切片集群模式
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群(Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步:
根据键值对的 key,按照 CRC16 算法 (opens new window)计算一个 16 bit 的值。
再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
接下来的问题就是,这些哈希槽怎么被映射到具体的 Redis 节点上的呢?有两种方案:
平均分配: 在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群节点上。比如集群中有 9 个节点,则每个节点上槽的个数为 16384/9 个。
手动分配: 可以使用 cluster meet 命令手动建立节点间的连接,组成集群,再使用 cluster addslots 命令,指定每个节点上的哈希槽个数。
为了方便你的理解,通过一张图来解释数据、哈希槽,以及节点三者的映射分布关系。
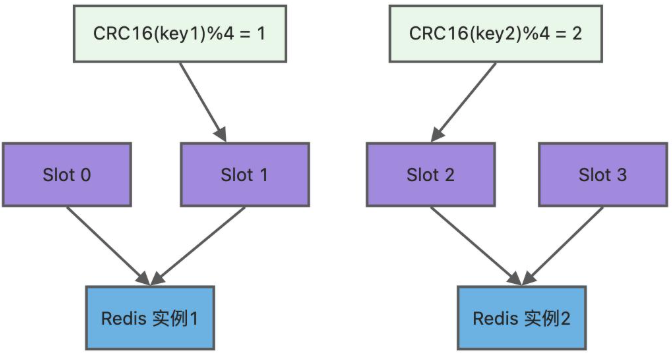
上图中的切片集群一共有 2 个节点,假设有 4 个哈希槽(Slot 0~Slot 3)时,我们就可以通过命令手动分配哈希槽,比如节点 1 保存哈希槽 0 和 1,节点 2 保存哈希槽 2 和 3。
redis-cli -h 192.168.1.1 –p 6379 cluster addslots 0,1
redis-cli -h 192.168.1.2 –p 6379 cluster addslots 2,3然后在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 4 进行取模,再根据各自的模数结果,就可以被映射到哈希槽 1(对应节点1) 和 哈希槽 2(对应节点2)。
需要注意的是,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
2.3 Redis Cluster实战配置
集群配置:
# redis-cluster.conf(6节点:3主3从)
port 7000
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
appendonly yesSpring Boot集成:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency> spring:
redis:
cluster:
nodes:
- 192.168.1.101:7000
- 192.168.1.101:7001
- 192.168.1.102:7000
- 192.168.1.102:7001
- 192.168.1.103:7000
- 192.168.1.103:7001
password: yourpassword
lettuce:
pool:
max-active: 100
max-idle: 50
min-idle: 10使用示例:
@Service
public class ProductCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public Product getProduct(String productId) {
String key = "product:" + productId;
// 1. 先查缓存
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 2. 缓存不存在,查数据库
product = productDao.getById(productId);
if (product == null) {
// 缓存空值(防止穿透)
redisTemplate.opsForValue().set(key, "", 5, TimeUnit.MINUTES);
return null;
}
// 3. 写入缓存
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
return product;
}
}2.4 Redis内存淘汰策略
Redis内存满时,如何淘汰数据?
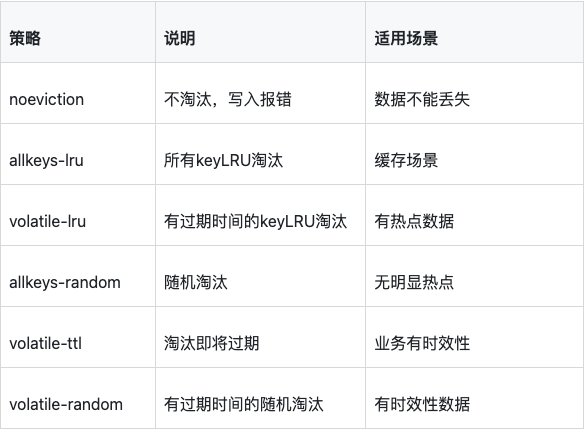
生产环境推荐:allkeys-lru(缓存场景)
# redis.conf
maxmemory 4gb
maxmemory-policy allkeys-lru三、缓存三大核心问题
3.1 缓存穿透
定义:查询一个不存在的数据,缓存和数据库都没有,每次请求都穿透到数据库。
问题场景:
public Product getProduct(String productId) {
String key = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 缓存没数据,查数据库
product = productDao.getById(productId);
// 问题:如果product为null,不写缓存
// 下次查询同样会穿透到数据库
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
return product;
}恶意请求大量查询不存在的ID,数据库压力剧增。
解决方案:
1. 缓存空值:
public Product getProduct(String productId) {
String key = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
product = productDao.getById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
} else {
// 缓存空值,过期时间短
redisTemplate.opsForValue().set(key, "", 5, TimeUnit.MINUTES);
}
return product;
}注意:空值过期时间要短(避免占用太多内存)。
2. 布隆过滤器:
public class BloomFilterCacheService {
private BloomFilter<String> bloomFilter;
@PostConstruct
public void init() {
// 初始化布隆过滤器(预估元素数量)
bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
1000000, // 预估元素数
0.01 // 误判率1%
);
// 加载所有存在的ID到布隆过滤器
List<String> allIds = productDao.getAllIds();
for (String id : allIds) {
bloomFilter.put(id);
}
}
public Product getProduct(String productId) {
// 1. 布隆过滤器判断是否存在
if (!bloomFilter.mightContain(productId)) {
// 不存在,直接返回
return null;
}
// 2. 存在(可能误判),查缓存
String key = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 3. 查数据库
product = productDao.getById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
return product;
}
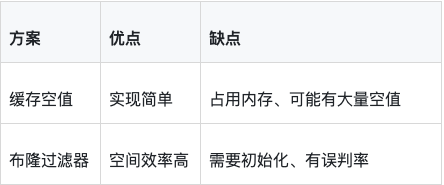
}布隆过滤器特点:
判断不存在:一定不存在
判断存在:可能存在(有误判率)
空间效率高:100万元素只需约1MB
方案对比:
3.2 缓存击穿
定义:热点key过期瞬间,大量请求同时穿透到数据库。
问题场景:
1. 商品A是热点,缓存30分钟
2. 30分钟到期,缓存过期
3. 此时1000个请求同时到达
4. 1000个请求都查缓存失败,都去查数据库
5. 数据库瞬间承受1000倍压力解决方案:
1. 热点数据永不过期:
// 热点商品缓存不设过期时间
if (isHotProduct(productId)) {
redisTemplate.opsForValue().set(key, product); // 无过期时间
} else {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
// 后台定时更新热点缓存
@Scheduled(fixedRate = 600000) // 每10分钟
public void refreshHotProducts() {
List<String> hotIds = getHotProductIds();
for (String id : hotIds) {
Product product = productDao.getById(id);
redisTemplate.opsForValue().set("product:" + id, product);
}
}2. 加锁重建缓存:
public Product getProduct(String productId) {
String key = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 加锁,只让一个请求重建缓存
String lockKey = "lock:" + key;
try {
// 尝试获取锁
boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (locked) {
// 获取到锁,查数据库,重建缓存
product = productDao.getById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
return product;
} else {
// 没获取到锁,等待并重试
Thread.sleep(50);
return getProduct(productId); // 重试
}
} finally {
redisTemplate.delete(lockKey);
}
}3. 逻辑过期(提前预警):
// 数据结构:包含逻辑过期时间
public class CacheData<T> {
private T data;
private Long expireTime; // 逻辑过期时间
public boolean isExpired() {
return expireTime != null && System.currentTimeMillis() > expireTime;
}
}
public Product getProduct(String productId) {
String key = "product:" + productId;
CacheData<Product> cacheData = (CacheData<Product>) redisTemplate.opsForValue().get(key);
if (cacheData != null) {
if (!cacheData.isExpired()) {
// 未过期,直接返回
return cacheData.getData();
}
// 已过期,异步刷新
asyncRefreshCache(productId);
// 返回旧数据(用户能接受短暂不一致)
return cacheData.getData();
}
// 缓存不存在,同步加载
return syncLoadCache(productId);
}
@Async
public void asyncRefreshCache(String productId) {
Product product = productDao.getById(productId);
CacheData<Product> cacheData = new CacheData<>();
cacheData.setData(product);
cacheData.setExpireTime(System.currentTimeMillis() + 30 * 60 * 1000);
redisTemplate.opsForValue().set("product:" + productId, cacheData);
}3.3 缓存雪崩
定义:大量key同时过期,或Redis节点故障,导致请求集中访问数据库。
问题场景:
场景1:批量设置相同过期时间
- 批量导入数据,都设置30分钟过期
- 30分钟后,全部同时过期
- 数据库瞬间承受压力
场景2:Redis节点故障
- 主节点故障,切换到从节点
- 切换期间,缓存不可用
- 所有请求穿透到数据库解决方案:
1. 过期时间加随机值:
// 原方案:固定30分钟
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
// 优化方案:30分钟 + 随机0-5分钟
int randomExpire = 30 * 60 + RandomUtils.nextInt(0, 5 * 60);
redisTemplate.opsForValue().set(key, product, randomExpire, TimeUnit.SECONDS);2. 多级缓存:
public class MultiLevelCacheService {
// L1:本地缓存(Caffeine)
private Cache<String, Product> localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public Product getProduct(String productId) {
// 1. 先查本地缓存
Product product = localCache.getIfPresent(productId);
if (product != null) {
return product;
}
// 2. 查Redis缓存
String key = "product:" + productId;
product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
localCache.put(productId, product); // 写入本地缓存
return product;
}
// 3. 查数据库
product = productDao.getById(productId);
if (product != null) {
localCache.put(productId, product);
redisTemplate.opsForValue().set(key, product, 30 + RandomUtils.nextInt(0, 5), TimeUnit.MINUTES);
}
return product;
}
}多级缓存:
L1本地缓存:响应最快,容量小
L2分布式缓存:容量大,跨实例共享
L3数据库:兜底
Redis故障时,本地缓存仍能响应。
3. Redis高可用部署:
Redis Cluster:多主多从,自动故障转移
+ 哨兵监控:主节点故障自动切换
+ 持久化:AOF + RDB,数据不丢失
+ 客户端重试:连接失败自动重试4. 限流降级:
// Redis不可用时,限流保护数据库
public Product getProductWithFallback(String productId) {
try {
return getProduct(productId);
} catch (RedisConnectionException e) {
// Redis故障,限流查询数据库
if (rateLimiter.tryAcquire()) {
return productDao.getById(productId);
} else {
// 限流触发,返回降级数据
return getFallbackProduct(productId);
}
}
}四、缓存与数据库一致性
4.1 一致性问题的本质
缓存和数据库是两个独立的存储,更新时可能出现不一致:
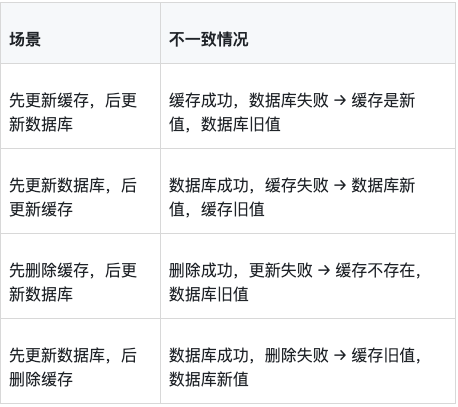
4.2 各种方案对比
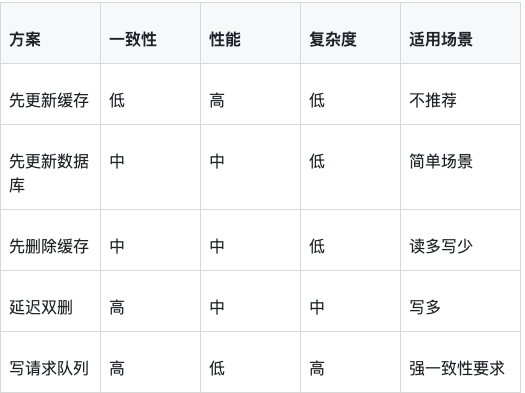
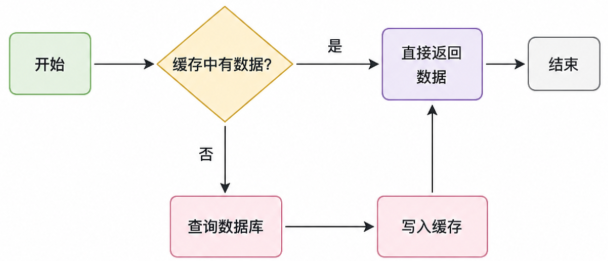
4.3 Cache Aside Pattern(旁路缓存)
最常用的模式:读时填充,写时失效。
读流程:
写流程:

public Product getProduct(String productId) {
String key = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
product = productDao.getById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
return product;
}
@Transactional
public void updateProduct(Product product) {
// 1. 更新数据库
productDao.update(product);
// 2. 删除缓存(让下次读取时重新加载)
String key = "product:" + product.getId();
redisTemplate.delete(key);
}为什么是删除而不是更新缓存?
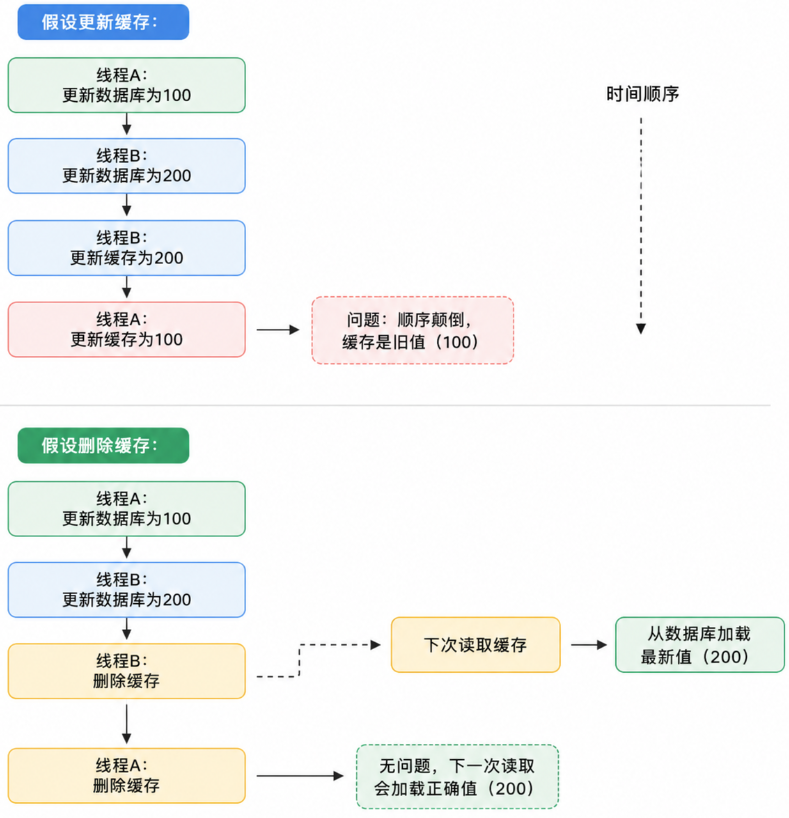
4.4 延迟双删
解决并发读写导致的脏数据:
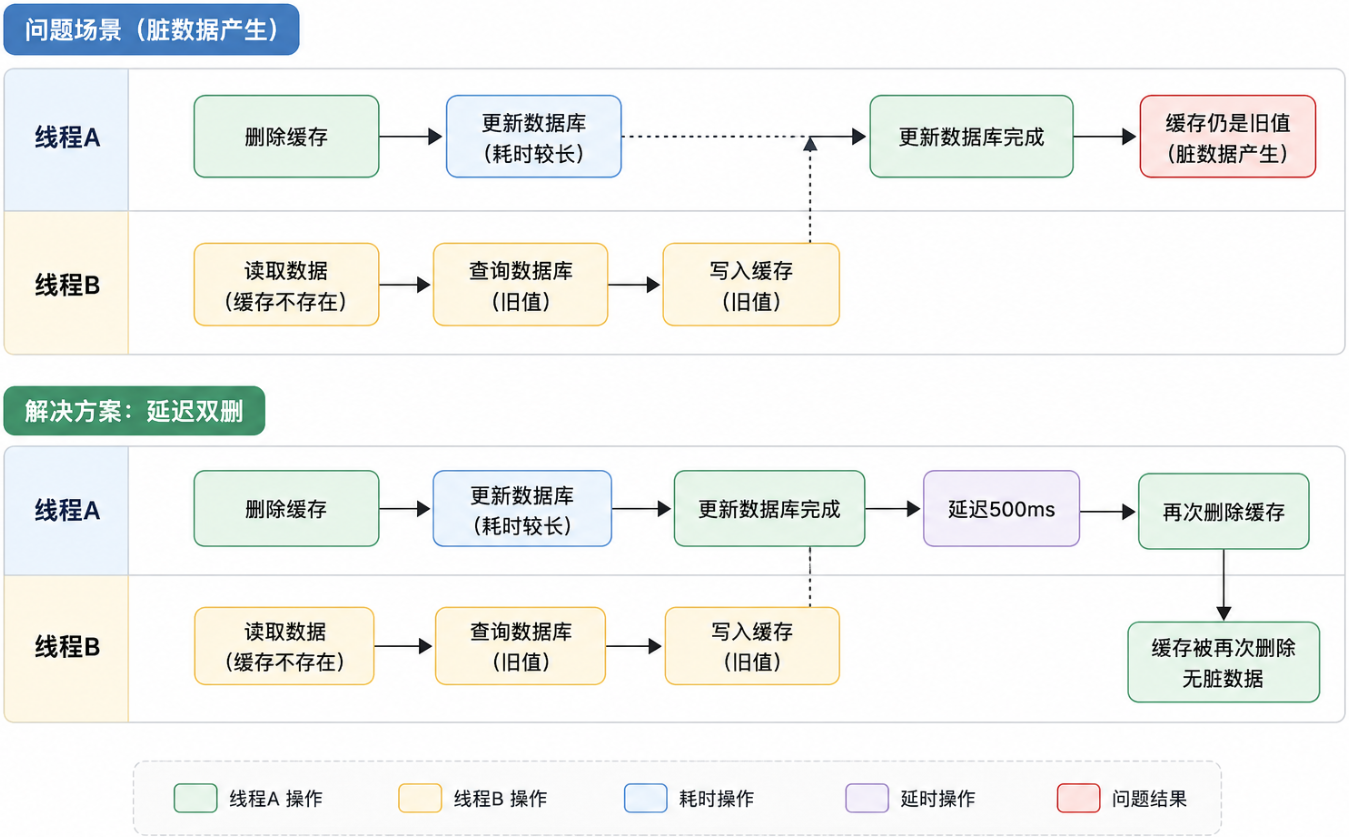
@Transactional
public void updateProduct(Product product) {
String key = "product:" + product.getId();
// 1. 第一次删除缓存
redisTemplate.delete(key);
// 2. 更新数据库
productDao.update(product);
// 3. 延迟双删(异步)
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(500); // 延迟500ms
redisTemplate.delete(key);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}延迟时间设置:根据数据库更新耗时,一般500ms-1s。
4.5 订阅数据库变更(Canal)
通过Canal监听MySQL binlog,自动同步缓存:
// Canal监听器
@CanalEventListener(schema = "product_db", table = "product")
public class ProductCanalListener {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@ListenPoint(destination = "example", schema = "product_db", table = "product")
public void onUpdate(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
// 数据库更新后,删除缓存
String productId = rowData.getAfterColumnsList().get(0).getValue();
String key = "product:" + productId;
redisTemplate.delete(key);
}
}优点:
解耦:业务代码不感知缓存更新
可靠:binlog保证数据变更不丢失
异步:不影响业务性能
4.6 最终一致性 vs 强一致性
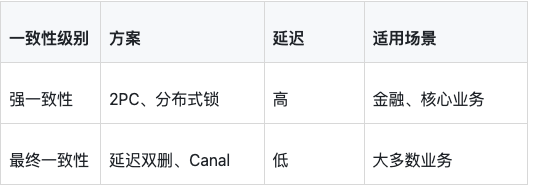
实际业务中,大部分场景可以接受短暂不一致:
商品信息更新,几分钟后缓存同步
用户信息修改,下次登录时生效
五、热点缓存处理
5.1 热点数据的识别
识别方法:
// Redis统计热点key
public List<String> getHotKeys() {
// 使用Redis的MEMORY USAGE或访问频率统计
// 或通过客户端代理统计
return hotKeyDetector.detectHotKeys();
}
// 或在应用层统计
private LoadingCache<String, AtomicLong> accessCounter = CacheBuilder.newBuilder()
.expireAfterWrite(1, TimeUnit.HOURS)
.build(new CacheLoader<String, AtomicLong>() {
@Override
public AtomicLong load(String key) {
return new AtomicLong(0);
}
});
public void recordAccess(String key) {
accessCounter.getUnchecked(key).incrementAndGet();
}
public List<String> getHotKeys(int threshold) {
return accessCounter.asMap().entrySet()
.stream()
.filter(e -> e.getValue().get() > threshold)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}5.2 热点数据分散
问题:热点key集中在一个Redis节点,单节点压力过大。
解决方案:热点key加随机后缀,分散到多个节点。
// 原方案:热点商品缓存
String key = "product:hot-001";
// 优化方案:加随机后缀,分散到多个key
String key1 = "product:hot-001#1";
String key2 = "product:hot-001#2";
String key3 = "product:hot-001#3";
// 读取时随机选择一个
public Product getHotProduct(String productId) {
int suffix = ThreadLocalRandom.current().nextInt(1, 4);
String key = "product:" + productId + "#" + suffix;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 缓存未命中,查数据库,写入多个key
product = productDao.getById(productId);
if (product != null) {
for (int i = 1; i <= 3; i++) {
redisTemplate.opsForValue().set(
"product:" + productId + "#" + i,
product,
30, TimeUnit.MINUTES
);
}
}
return product;
}热点key分散到3个key,压力降低3倍。
5.3 本地缓存热点数据
// 热点数据优先本地缓存
public class HotProductCacheService {
// 本地缓存(容量小、速度快)
private Cache<String, Product> localCache = Caffeine.newBuilder()
.maximumSize(1000) // 只存1000个热点
.expireAfterWrite(1, TimeUnit.MINUTES)
.recordStats() // 记录统计信息
.build();
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public Product getProduct(String productId) {
// 1. 热点数据查本地缓存
Product product = localCache.getIfPresent(productId);
if (product != null) {
return product;
}
// 2. 查Redis
String key = "product:" + productId;
product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
// Redis命中,写入本地缓存
localCache.put(productId, product);
return product;
}
// 3. 查数据库
product = productDao.getById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
// 热点判断(可根据访问频率)
if (isHot(productId)) {
localCache.put(productId, product);
}
}
return product;
}
private boolean isHot(String productId) {
// 根据访问频率判断
return hotKeyDetector.isHot(productId);
}
}六、实战经验与踩坑总结
6.1 大Key问题
问题:单个key存储数据过大,如几MB的JSON。
影响:
内存占用大
读写性能下降
网络传输慢
可能导致节点内存溢出
排查:
# Redis命令:查看key内存占用
MEMORY USAGE product:12345解决方案:
// 原方案:存储整个商品对象(可能很大)
Product product = new Product();
product.setDetail("很长的商品详情...");
redisTemplate.opsForValue().set("product:12345", product);
// 优化方案:拆分大对象
// 基础信息单独存
redisTemplate.opsForValue().set("product:12345:basic", basicInfo);
// 详情单独存
redisTemplate.opsForValue().set("product:12345:detail", detail);
// 或使用Hash结构
redisTemplate.opsForHash().put("product:12345", "basic", basicInfo);
redisTemplate.opsForHash().put("product:12345", "detail", detail);6.2 Key过期事件监听
问题场景:需要在key过期时执行某些操作。
Redis过期通知:
// 配置Redis监听过期事件
@Configuration
public class RedisConfig {
@Bean
public RedisMessageListenerContainer redisMessageListenerContainer(
RedisConnectionFactory connectionFactory) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
return container;
}
}
@Component
public class KeyExpirationListener {
@EventListener
public void handleExpiration(RedisKeyExpiredEvent event) {
String expiredKey = event.getKeyspace();
// 处理过期逻辑
log.info("Key expired: {}", expiredKey);
}
}注意:Redis过期通知不可靠:
可能丢失(Redis重启)
事件通知有延迟
只通知key,不通知value
可靠方案:定时任务扫描即将过期key
@Scheduled(fixedRate = 60000)
public void checkExpiringKeys() {
// 扫描即将过期的key(需要额外存储过期时间)
Set<String> keys = redisTemplate.opsForZSet()
.rangeByScore("expiring_keys", 0, System.currentTimeMillis() + 60000);
for (String key : keys) {
// 提前处理
handleExpiringKey(key);
}
}6.3 缓存预热问题
问题:系统启动时缓存为空,瞬间大量请求穿透。
解决方案:启动时预加载热点数据
@Component
public class CachePreloader implements ApplicationRunner {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Override
public void run(ApplicationArguments args) {
// 加载热点数据到缓存
preloadHotProducts();
preloadHotUsers();
}
private void preloadHotProducts() {
List<Product> hotProducts = productDao.getHotProducts();
for (Product product : hotProducts) {
String key = "product:" + product.getId();
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
log.info("预加载热点商品 {} 个", hotProducts.size());
}
}6.4 分布式锁与缓存结合
场景:热点key重建缓存时,用分布式锁防止并发重建。
public Product getProductWithLock(String productId) {
String key = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 分布式锁重建缓存
String lockKey = "lock:product:" + productId;
RLock lock = redisson.getLock(lockKey);
try {
if (lock.tryLock(10, 30, TimeUnit.SECONDS)) {
// 获取锁后再次检查缓存(避免重复重建)
product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 查数据库,重建缓存
product = productDao.getById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
}
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
return product;
}七、分布式缓存最佳实践
7.1 Key命名规范
// 好的命名:业务:对象:ID
"product:info:12345"
"user:profile:1001"
"order:detail:20240115001"
// 坏的命名:无层级、难理解
"p_12345"
"u1001"
"order-2024-01-15-001"7.2 过期时间设置原则
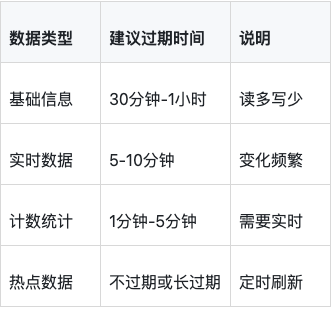
7.3 缓存使用原则
原则1:不缓存频繁变化的数据
// 不推荐:库存变化频繁,缓存容易不一致
redisTemplate.opsForValue().set("stock:" + productId, stock);
// 推荐:直接用Redis原子操作
redisTemplate.opsForValue().decrement("stock:" + productId);原则2:缓存要有兜底
try {
return getProduct(productId);
} catch (RedisException e) {
// Redis故障,直接查数据库
return productDao.getById(productId);
}原则3:监控缓存健康
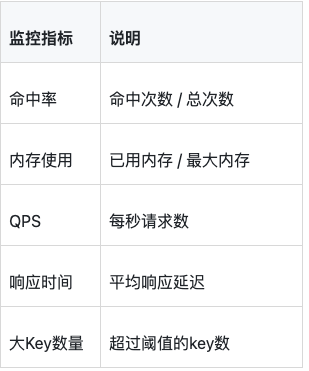
八、常见问题解答
Q1:Redis和Memcached选哪个?
Redis优势:数据结构丰富、持久化、主从复制、集群。 Memcached优势:纯内存、多线程、简单。 大多数场景推荐Redis。
Q2:缓存命中率多少算正常?
一般场景60%-80%算正常。热点场景可达90%+。命中率低需要排查:过期时间、缓存容量、业务特征。
Q3:本地缓存和分布式缓存怎么配合?
本地缓存存热点数据(容量小)。分布式缓存存所有数据(容量大)。热点数据优先本地缓存,本地未命中再查分布式。
Q4:Redis集群最少几个节点?
Redis Cluster官方建议至少6节点:3主3从。单机或主从适合小规模,集群适合大规模。
Q5:缓存一致性问题怎么处理最可靠?
强一致性:分布式锁。最终一致性:延迟双删或Canal监听。根据业务需求选择。
Q6:热点数据怎么处理最有效?
识别热点 → 本地缓存 + 分布式缓存 → 分散key → 分布式锁重建。
九、总结
分布式缓存不只是"加个Redis就快了",需要系统考虑:
架构设计:
Redis Cluster分布数据
主从复制保证高可用
哨兵监控故障转移
核心问题:
穿透:布隆过滤器或缓存空值
击穿:分布式锁重建缓存
雪崩:过期时间随机化 + 多级缓存
一致性:
Cache Aside:先更新数据库后删除缓存
延迟双删:防止并发脏数据
Canal监听:异步同步
热点处理:
本地缓存热点数据
分散热点key到多个节点
分布式锁防止并发重建
最佳实践:
Key命名规范
过期时间合理
缓存要有兜底
监控缓存健康
用好分布式缓存,能让系统性能提升10倍以上。但关键是理解各种问题的本质,选择合适的方案,并做好监控兜底。
评论区