

摘要:本文从 Java 后端开发的真实场景出发,系统讲清数据库事务的 ACID、隔离级别、锁与 MVCC,JDBC 事务的提交和回滚机制,以及 Spring @Transactional 的传播行为、回滚规则、失效场景和生产实践。适合想彻底理解 Java 事务、数据库事务和 Spring 事务边界的开发者阅读。
写在前面:事务不是一句 @Transactional
很多人第一次接触事务,是在 Service 方法上加一行注解:
@Transactional
public void createOrder(CreateOrderCommand command) {
// 扣库存
// 创建订单
// 写支付单
}代码看起来很安心。只要中间报错,前面都回滚。问题是,线上事故往往就藏在这份安心里:
为什么方法明明加了
@Transactional,数据还是提交了?为什么捕获异常以后事务没有回滚?
为什么一个方法里调用另一个事务方法,传播行为没生效?
为什么库存明明判断大于 0,最后还是超卖?
为什么查询接口也会被事务拖慢?
为什么本地测试没问题,上线后出现死锁、锁等待、脏数据?
事务不是注解魔法。它是一套横跨数据库、连接、JDBC、ORM、Spring AOP 和业务边界的机制。要真正用好事务,至少要同时理解三层:
第一层是数据库事务。它解决数据一致性问题,但也引入锁、隔离级别、死锁、快照读等复杂行为。
第二层是 Java 事务。JDBC 通过 Connection 控制事务,ORM 框架在此基础上做了封装。
第三层是 Spring 事务。@Transactional 通过 AOP 把事务管理织入业务方法,但它有明确边界,也有不少失效场景。
一、事务到底解决什么问题
事务解决的是一组操作的“一致性边界”。以创建订单为例,通常至少包含几件事:
校验库存。
扣减库存。
创建订单。
创建支付记录。
写操作日志。
如果库存扣了,订单没生成,用户会投诉;如果订单生成了,支付记录没写,后续对账会痛苦;如果日志写失败导致主流程回滚,业务又可能不接受。
事务的核心价值是:把必须一起成功、一起失败的操作放到同一个边界里。
注意:这句话里的“必须”。不是所有操作都应该放进同一个事务。发短信、发 MQ、调外部支付、写搜索索引,很多时候都不应该和数据库主流程绑成一个本地事务。事务边界过大,会让系统慢、锁重、失败面变大。
一个好事务,往往不是“包住尽可能多的代码”,而是“刚好包住必须保持一致的状态变更”。
二、数据库事务的 ACID
数据库事务通常用 ACID 描述。
1. Atomicity:原子性
原子性表示事务里的操作要么全部成功,要么全部失败。比如转账:
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;不能只扣 A 的钱,不给 B 加钱。只要第二条失败,第一条也必须回滚。
2. Consistency:一致性
一致性表示事务执行前后,数据都要满足业务约束和数据库约束。例如:
余额不能小于 0。
订单状态不能从
CANCELLED变成PAID。子表不能引用不存在的主表记录。
一致性不是数据库一个人保证的。数据库能保证主键、唯一索引、外键、非空等约束;业务状态机、金额校验、库存规则,还要靠应用代码和设计共同保证。
3. Isolation:隔离性
隔离性表示多个事务并发执行时,一个事务不应该被另一个事务的中间状态干扰。
问题也在这里。隔离越强,并发越低;隔离越弱,并发越高,但异常现象越多。数据库隔离级别就是在一致性和性能之间做取舍。
4. Durability:持久性
持久性表示事务提交后,数据修改应该持久保存,即使数据库进程崩溃也不能随便丢。
在 MySQL InnoDB 里,这和 redo log、binlog、刷盘策略等机制有关。日常开发不一定每天接触这些细节,但要知道:提交成功不是“内存里改了”,而是数据库承诺这次修改已经进入可靠恢复链路。
三、事务隔离级别:最容易被低估的基础
SQL 标准定义了四个隔离级别:
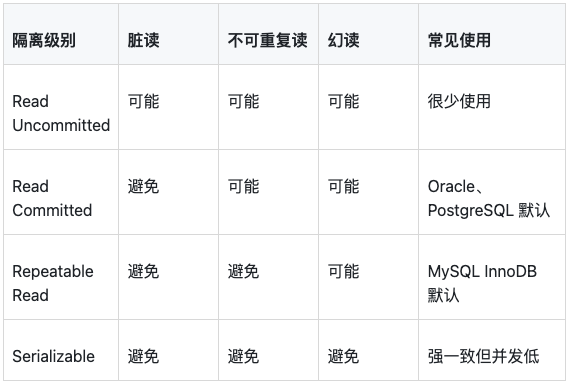
1. 脏读
一个事务读到了另一个事务还没提交的数据。
比如事务 A 修改余额为 50,但还没提交;事务 B 读到了 50。随后事务 A 回滚,事务 B 刚才读到的就是脏数据。
2. 不可重复读
同一个事务里,两次读取同一行,结果不同。
事务 A 第一次读余额是 100;事务 B 提交修改,把余额改成 80;事务 A 第二次读到 80。这就是不可重复读。
3. 幻读
同一个事务里,两次按条件查询,第二次多出或少了符合条件的行。
事务 A 查询“未支付订单”有 10 条;事务 B 新增一条未支付订单并提交;事务 A 再查变成 11 条。这就是幻读。
4. MySQL InnoDB 的 Repeatable Read 不是简单的标准 RR
MySQL InnoDB 默认隔离级别是 Repeatable Read。它通过 MVCC 让普通 SELECT 在同一事务里读到一致性快照,所以很多读场景下不会出现不可重复读。
但一旦你使用当前读,例如:
SELECT * FROM product WHERE id = 1 FOR UPDATE;
UPDATE product SET stock = stock - 1 WHERE id = 1;数据库就会读取最新已提交版本,并加锁。快照读和当前读混在一起,是很多并发问题的来源。
简单记:
普通
SELECT多数是快照读。SELECT ... FOR UPDATE、SELECT ... LOCK IN SHARE MODE、UPDATE、DELETE是当前读。当前读会涉及锁竞争。
四、锁、MVCC 与并发一致性
事务隔离不是凭空来的,底层通常靠锁和 MVCC。
1. 行锁不是“锁一行”这么简单
在 InnoDB 里,锁和索引强相关。更新语句如果命中索引,通常锁定相关索引记录;如果条件没有走索引,可能扫描大量记录,锁范围也会变大。例如:
UPDATE user SET status = 1 WHERE phone = '13800000000';如果 phone 没有索引,这条语句可能扫描很多行。即使最后只改一条,锁影响范围也可能远超预期。所以事务优化的第一条经验是:事务里的更新条件要尽量走索引。
2. MVCC 让读写少互相阻塞
MVCC,全称 Multi-Version Concurrency Control,多版本并发控制。它的大概思路是:
数据被修改时,不是简单覆盖旧值,而是保留版本链。读事务可以根据自己的 Read View 读取某个历史版本,写事务则修改最新版本。这就是为什么很多普通查询不会被更新阻塞。它读的是快照,不一定读最新值。但 MVCC 不是万能的。涉及写入、唯一索引、外键检查、当前读、范围更新时,锁依然会出现。
3. 死锁不是数据库坏了
死锁是两个事务互相等待对方释放锁。经典例子:
事务 A:
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;事务 B:
UPDATE account SET balance = balance - 50 WHERE id = 2;
UPDATE account SET balance = balance + 50 WHERE id = 1;A 先锁 id=1,B 先锁 id=2,然后双方都等对方释放另一行。数据库检测到死锁后,会回滚其中一个事务。
降低死锁概率的常用做法:
多行更新按固定顺序加锁,例如统一按 id 升序。
事务尽量短,不在事务里做远程调用。
更新条件走索引。
拆分大事务。
对可重试业务增加死锁重试。
五、JDBC 事务:Java 事务的底层入口
Spring 事务再高级,底层也绕不开 JDBC Connection。
要在JDBC中执行事务,本质上就是如何把多条SQL包裹在一个数据库事务中执行。我们来看JDBC的事务代码:
Connection conn = openConnection();
try {
// 关闭自动提交:
conn.setAutoCommit(false);
// 执行多条SQL语句:
insert(); update(); delete();
// 提交事务:
conn.commit();
} catch (SQLException e) {
// 回滚事务:
conn.rollback();
} finally {
conn.setAutoCommit(true);
conn.close();
}
其中,开启事务的关键代码是conn.setAutoCommit(false),表示关闭自动提交。提交事务的代码在执行完指定的若干条SQL语句后,调用conn.commit()。要注意事务不是总能成功,如果事务提交失败,会抛出SQL异常(也可能在执行SQL语句的时候就抛出了),此时我们必须捕获并调用conn.rollback()回滚事务。最后,在finally中通过conn.setAutoCommit(true)把Connection对象的状态恢复到初始值。
实际上,默认情况下,我们获取到Connection连接后,总是处于“自动提交”模式,也就是每执行一条SQL都是作为事务自动执行的,这也是为什么前面几节我们的更新操作总能成功的原因:因为默认有这种“隐式事务”。只要关闭了Connection的autoCommit,那么就可以在一个事务中执行多条语句,事务以commit()方法结束。
如果要设定事务的隔离级别,可以使用如下代码:
// 设定隔离级别为READ COMMITTED:
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
如果没有调用上述方法,那么会使用数据库的默认隔离级别。MySQL的默认隔离级别是REPEATABLE_READ。
这里有几个关键点:
setAutoCommit(false)开启手动事务。多条 SQL 必须使用同一个
Connection。成功后
commit()。失败后
rollback()。最后归还连接。
Spring 做的事,本质上就是把这些重复、容易出错的代码统一管理起来。
六、Spring 事务的核心原理
Spring 事务的核心是 PlatformTransactionManager。常见实现:
DataSourceTransactionManager:用于 JDBC、MyBatis。JpaTransactionManager:用于 JPA、Hibernate。JtaTransactionManager:用于分布式 / XA 事务,普通业务较少直接使用。
当你在方法上加:
@Transactional
public void pay(Long orderId) {
// business code
}Spring 通常会通过 AOP 生成代理对象。调用代理方法时,大致流程是:
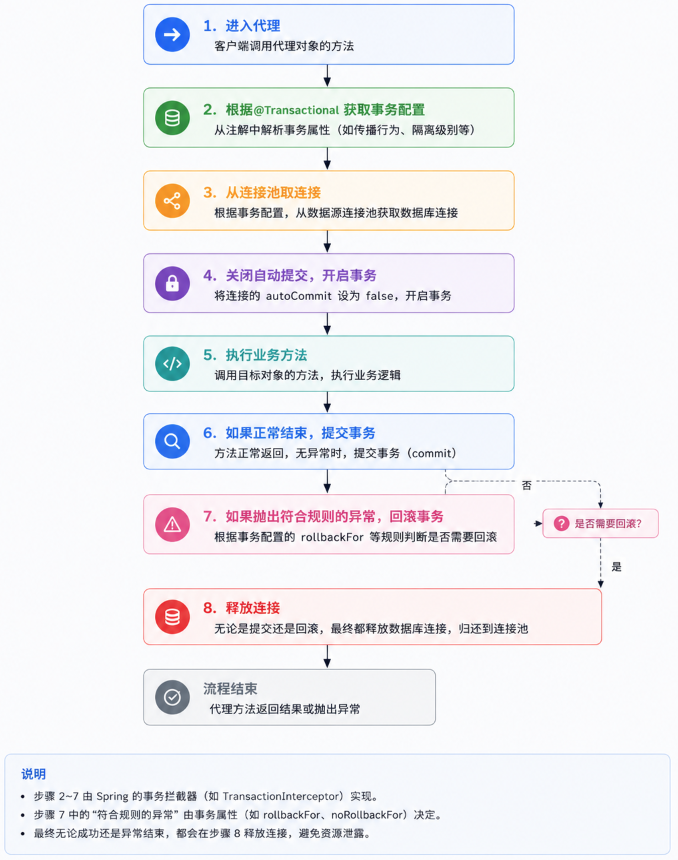
所以,@Transactional 不是改写数据库能力,而是帮你在方法边界上管理连接和提交回滚。
七、Spring @Transactional 常用配置
1. rollbackFor:回滚规则
默认情况下,Spring 只会对 RuntimeException 和 Error 回滚,对受检异常不回滚。比如:
@Transactional
public void importUser() throws IOException {
userRepository.save(user);
throw new IOException("file error");
}这段代码默认不会因为 IOException 回滚。很多人第一次遇到时会很意外。
如果希望所有异常都回滚,可以写:
@Transactional(rollbackFor = Exception.class)
public void importUser() throws IOException {
userRepository.save(user);
throw new IOException("file error");
}不过不要无脑全局套 rollbackFor = Exception.class。有些业务异常可能只是提示用户,并不代表前面的数据应该回滚。规则要跟业务语义一致。
2. readOnly:只读事务
查询方法可以标记只读:
@Transactional(readOnly = true)
public OrderDetail getOrderDetail(Long orderId) {
return orderRepository.findDetail(orderId);
}readOnly = true 的作用不是绝对禁止写入,它更多是给事务管理器、ORM 和数据库一个优化提示。不同数据库和框架的实际效果不完全一样。
经验上,复杂查询、需要一致性快照的读逻辑,可以使用只读事务;普通单表查询不一定非要加事务。
3. timeout:事务超时
@Transactional(timeout = 3)
public void createOrder(CreateOrderCommand command) {
// must finish in 3 seconds
}事务超时能避免某些事务长期占用连接和锁。但它不是万能救命绳。真正要解决的还是慢 SQL、外部调用、锁等待和事务边界过大。
4. isolation:隔离级别
@Transactional(isolation = Isolation.READ_COMMITTED)
public void settle() {
// settlement logic
}不要轻易提高隔离级别到 SERIALIZABLE。它确实强,但并发性能代价很大。
多数业务可以使用数据库默认隔离级别。真正需要改隔离级别时,最好先写清楚要避免什么问题:脏读、不可重复读、幻读,还是业务层面的并发覆盖。
八、事务传播行为:Spring 事务最容易混乱的一块
传播行为决定“一个事务方法调用另一个事务方法时,该用现有事务,还是新开事务”。常见传播行为如下:
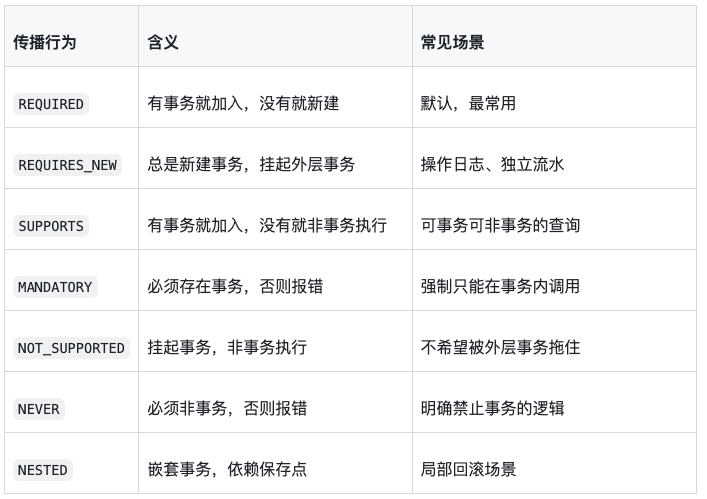
1. REQUIRED:默认选择
@Transactional
public void createOrder() {
deductStock();
saveOrder();
}默认就是 REQUIRED。如果外层已有事务,就加入外层;没有就新建。大多数业务方法用它就够了。
2. REQUIRES_NEW:独立提交
典型场景是操作日志:
@Transactional
public void pay(Long orderId) {
orderRepository.markPaid(orderId);
auditLogService.record("pay success");
throw new RuntimeException("mock failure");
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void record(String message) {
auditLogRepository.save(new AuditLog(message));
}如果 record 真的通过 Spring 代理调用,它会开启新事务。即使外层 pay 回滚,日志也能独立提交。但这也带来一个问题:日志提交了,主事务回滚了。到底是不是你想要的结果?要按业务判断。
3. NESTED:保存点,不等于 REQUIRES_NEW
NESTED 依赖数据库保存点。内层失败可以回滚到保存点,外层事务还可以继续。它和 REQUIRES_NEW 最大区别是:
REQUIRES_NEW是独立事务,有自己的提交和回滚。NESTED仍在外层事务里,外层最终回滚时,内层也保不住。
很多项目其实用不到 NESTED。如果你不确定它的行为,宁愿别用。
九、Spring 事务失效的常见场景
这是最实用的一部分。线上很多事务问题,不是数据库不会回滚,而是事务根本没生效。
1. 同类方法自调用
@Service
public class OrderService {
public void create() {
this.saveOrder();
}
@Transactional
public void saveOrder() {
// insert order
}
}create() 里用 this.saveOrder(),不会经过 Spring 代理,事务不会生效。
解决方式:
把事务方法拆到另一个 Spring Bean。
从 Spring 容器拿代理对象调用。
调整事务边界,把
@Transactional放到入口 public 方法上。
最推荐的是第三种:让事务边界贴近业务用例入口。
2. 方法不是 public
Spring 基于代理的声明式事务通常要求事务方法是 public。如果你把 @Transactional 加在 private 方法上,多数情况下不会按你期待的方式生效。
@Transactional
private void saveOrder() {
// not recommended
}别这么写。事务方法保持 public,边界清楚,后续排查也省事。
3. 异常被吃掉了
@Transactional
public void createOrder() {
try {
orderRepository.save(order);
stockRepository.deduct(stockId);
} catch (Exception e) {
log.error("create order failed", e);
}
}异常被 catch 了,方法正常返回,Spring 以为业务成功,于是提交事务。
如果需要回滚,要么继续抛出异常:
catch (Exception e) {
log.error("create order failed", e);
throw e;
}要么手动标记回滚:
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();手动标记可以用,但别滥用。代码里到处 setRollbackOnly(),维护体验会很差。
4. 抛出受检异常但没有配置 rollbackFor
前面提过,受检异常默认不回滚:
@Transactional
public void upload() throws IOException {
fileRecordRepository.save(record);
throw new IOException("upload failed");
}需要:
@Transactional(rollbackFor = IOException.class)
public void upload() throws IOException {
// ...
}或者统一用业务运行时异常包装:
throw new BizException("upload failed", e);5. 数据库表不支持事务
MySQL 里 InnoDB 支持事务,MyISAM 不支持事务。现在新项目一般不会主动用 MyISAM,但老系统迁移时还真可能遇到。排查时可以看:
SHOW TABLE STATUS WHERE Name = 'your_table';如果引擎不支持事务,Spring 配得再漂亮也没用。
6. 多数据源事务没有正确配置
一个方法里操作两个数据库:
@Transactional
public void sync() {
userDbRepository.save(user);
orderDbRepository.save(order);
}如果只是普通本地事务,通常只能管理一个数据源。另一个数据源可能已经提交,导致部分成功。这时要考虑:
是否可以改成最终一致。
是否用消息、Outbox、补偿任务。
是否真的需要分布式事务。
多数据源事务管理器是否配置正确。
不要默认以为一个 @Transactional 能管住所有数据库。
十、事务和业务设计:别把外部调用放进事务
下面这种代码很常见,也很危险:
@Transactional
public void createOrder(CreateOrderCommand command) {
orderRepository.save(order);
stockRepository.deduct(command.getSkuId());
paymentClient.createPayment(order.getId());
smsClient.sendOrderCreatedMessage(order.getUserId());
}问题很多:
外部接口慢,数据库连接和锁会一直被占用。
外部接口成功后,数据库事务可能回滚。
数据库提交成功后,短信可能失败。
网络抖动会放大事务耗时。
更稳的方式通常是:
本地事务只处理核心状态变更。
在同一事务里写 Outbox 事件表。
事务提交后由异步任务或 MQ 发送外部消息。
外部调用失败时通过重试和补偿处理。
示意:
@Transactional
public void createOrder(CreateOrderCommand command) {
Order order = orderRepository.save(command.toOrder());
stockRepository.deduct(command.getSkuId());
outboxRepository.save(OrderCreatedEvent.from(order));
}提交之后:
public void publishOutboxEvents() {
List<OutboxEvent> events = outboxRepository.findUnpublished();
for (OutboxEvent event : events) {
messagePublisher.publish(event);
outboxRepository.markPublished(event.getId());
}
}这不是银弹,但比在事务里直接调支付、短信、库存中台要可控得多。
十一、库存扣减:一个典型并发事务案例
假设有库存表:
CREATE TABLE product_stock (
product_id BIGINT PRIMARY KEY,
stock INT NOT NULL
);很多人会写:
@Transactional
public void deductStock(Long productId, int quantity) {
ProductStock stock = stockRepository.findByProductId(productId);
if (stock.getStock() < quantity) {
throw new BizException("库存不足");
}
stock.setStock(stock.getStock() - quantity);
stockRepository.save(stock);
}在高并发下,如果没有合适的锁或版本控制,两个事务都可能读到 stock=1,然后都扣减成功。
更常见的数据库侧写法是条件更新:
UPDATE product_stock
SET stock = stock - ?
WHERE product_id = ?
AND stock >= ?;Java 代码:
@Transactional
public void deductStock(Long productId, int quantity) {
int updated = stockMapper.deduct(productId, quantity);
if (updated == 0) {
throw new BizException("库存不足");
}
}对应 MyBatis:
<update id="deduct">
UPDATE product_stock
SET stock = stock - #{quantity}
WHERE product_id = #{productId}
AND stock >= #{quantity}
</update>这个写法把“判断库存”和“扣减库存”合成一条原子 SQL,避免了先查再改之间的并发窗口。
如果业务更复杂,比如要限制用户购买次数、活动库存、冻结库存、预占库存,就需要结合唯一索引、状态机、乐观锁、流水表来设计,而不是只靠一个事务注解硬扛。
十二、乐观锁与悲观锁
1. 乐观锁
乐观锁适合冲突不高的场景。常见做法是加 version 字段:
ALTER TABLE product_stock ADD COLUMN version INT NOT NULL DEFAULT 0;更新时带上版本:
UPDATE product_stock
SET stock = stock - ?,
version = version + 1
WHERE product_id = ?
AND version = ?
AND stock >= ?;如果更新行数为 0,说明版本变化或库存不足,可以重试或返回失败。
优点:
不长时间持有锁。
并发性能较好。
适合读多写少、冲突较低场景。
缺点:
高冲突时重试成本高。
业务代码要处理失败和重试。
2. 悲观锁
悲观锁适合冲突高、必须串行处理的场景:
SELECT * FROM product_stock
WHERE product_id = ?
FOR UPDATE;拿到锁后再判断和修改。
优点:
逻辑直观。
能强制串行化某些关键资源。
缺点:
锁等待影响吞吐。
容易出现死锁。
事务必须短。
选择乐观锁还是悲观锁,不是看哪个高级,而是看冲突概率、业务容忍度和系统吞吐目标。
十三、Spring 事务与 MyBatis、JPA 的关系
1. MyBatis
MyBatis 本身可以管理事务,但在 Spring 项目里,通常交给 Spring 管。只要 SqlSessionFactory 使用了 Spring 管理的数据源,并且配置了 DataSourceTransactionManager,同一个事务里的 MyBatis 操作会复用同一个连接。
常见误区是:一个 Service 里同时手动创建 SqlSession,又使用 Spring Mapper。这样很容易绕过 Spring 事务管理。
在 Spring Boot 项目里,正常使用 Mapper 注入即可:
@Service
public class OrderService {
private final OrderMapper orderMapper;
public OrderService(OrderMapper orderMapper) {
this.orderMapper = orderMapper;
}
@Transactional
public void create(Order order) {
orderMapper.insert(order);
}
}2. JPA
JPA 里还有一个持久化上下文。事务提交时,Hibernate 会 flush 变更到数据库。这意味着:
@Transactional
public void changeName(Long userId, String name) {
User user = userRepository.findById(userId).orElseThrow();
user.changeName(name);
}即使没有显式调用 save,提交时也可能更新数据库。这是 JPA 的脏检查机制。它很好用,但也要小心:
不要在事务里加载大量实体后随意修改。
查询方法如果不需要变更,尽量使用
readOnly = true。长事务会让持久化上下文越来越大。
十四、事务排查:线上问题怎么定位
事务问题通常不是一句日志能看出来。建议按下面顺序查。
1. 先确认事务是否真的生效
看几个点:
方法是不是 public。
是不是通过 Spring Bean 代理调用。
异常有没有被 catch。
异常类型是否触发回滚。
事务管理器是否配置正确。
数据源是否是同一个。
表引擎是否支持事务。
2. 打开 Spring 事务日志
开发和测试环境可以临时打开:
logging.level.org.springframework.transaction=TRACE
logging.level.org.springframework.jdbc.datasource.DataSourceTransactionManager=DEBUG如果是 JPA:
logging.level.org.springframework.orm.jpa.JpaTransactionManager=DEBUG日志里能看到事务创建、提交、回滚、挂起、恢复等信息。
3. 查数据库锁等待
MySQL 可以看:
SHOW ENGINE INNODB STATUS;也可以查 performance_schema 里的锁等待信息。不同 MySQL 版本表结构略有差异,但思路一样:找到谁在等锁、谁持有锁、SQL 是什么。
4. 看慢 SQL 和执行计划
事务慢,经常不是事务框架的问题,而是 SQL 慢。
EXPLAIN UPDATE product_stock
SET stock = stock - 1
WHERE product_id = 1001
AND stock >= 1;重点看:
有没有走索引。
扫描行数是否过大。
是否出现临时表、文件排序。
更新条件是否足够精确。
5. 看连接池
事务时间过长会占用连接。连接池耗尽以后,接口会排队,排队又会放大超时。需要关注:
活跃连接数。
等待连接数。
连接获取耗时。
最大连接数配置。
是否有连接泄漏。
事务、锁、连接池经常一起出问题。只盯着某一层,容易绕远。
结语:事务是工程边界,不只是数据库功能
事务最容易被误解成“失败了自动回滚”。这当然是它的一部分,但远远不够。在真实 Java 项目里,事务同时涉及:
数据库隔离级别。
锁和 MVCC。
SQL 是否走索引。
JDBC 连接是否一致。
Spring AOP 是否生效。
异常是否触发回滚。
多数据源是否能统一管理。
外部系统是否需要最终一致。
业务流程是否应该拆状态机。
如果只记住一句话,我建议记这句:事务边界就是一致性边界。
把必须一致的数据放进同一个本地事务;把不能放进去的外部动作,用事件、补偿、幂等和状态机管理。这样设计出来的系统,才不会在低并发时看着完美,一到线上就被锁等待、死锁、超卖和半成功状态反复教育。
@Transactional 很有用,但它不是护身符。真正可靠的事务设计,来自你对数据库、Java、Spring 和业务边界的共同理解。
评论区