摘要:本文全面介绍LangChain4j框架,从核心架构到实战应用,涵盖Spring Boot整合、对话记忆、Function Call、MCP协议、RAG检索增强生成、智能体开发及多智能体协作。适合Java开发者快速上手大模型应用开发。
前言:为什么Java开发者需要LangChain4j
在过去两年里,我一直在企业级Java项目中探索大模型应用落地的最佳实践。最开始尝试的是Python生态的LangChain,虽然功能强大,但团队的学习成本和与现有Spring Boot微服务架构的整合成本都很高。直到遇到LangChain4j,这个问题才真正得到解决。
如果你也在寻找一个能无缝融入Java生态的大模型开发框架,这篇文章会帮你快速理解LangChain4j的核心能力,并通过实战代码展示如何将它应用到真实项目中。
一、LangChain4j是什么
LangChain4j是一个专为Java和Kotlin开发者设计的大模型应用开发框架。它的名字虽然借鉴了Python生态中知名的LangChain,但并非简单的Java移植版,而是从Java开发者的视角重新设计了API和架构。
1.1 核心定位
简单来说,LangChain4j解决的是这三个问题:
模型接入层抽象 —— 无论你用OpenAI、Azure OpenAI、Anthropic Claude、Google Gemini,还是本地部署的Ollama、Llama,框架提供统一的接口。切换模型只需要改配置,不需要改业务代码。
能力组件化 —— 对话记忆、文档检索、工具调用、智能体编排这些通用能力,框架已经帮你封装好了。
企业级整合 —— 提供Spring Boot Starter,与Spring生态无缝集成,支持依赖注入、配置管理、健康检查等企业级特性。
1.2 与Python LangChain的对比
很多开发者会问:LangChain4j和Python的LangChain有什么区别?
从功能覆盖上看,两者基本对等。但从开发体验来说,LangChain4j有几个明显的Java特色:
- 类型安全:编译期就能发现API使用错误,而不是等到运行时才报错
- IDE友好:方法提示、参数补全、重构支持都更好
- 测试友好:Mock模型响应更容易,单元测试写起来更顺手
- 性能可控:Java的内存管理和并发模型对于高并发场景更可控
如果你所在团队的Java技术栈已经成熟,迁移到Python来开发AI应用的成本,往往比直接用LangChain4j要高得多。
二、LangChain4j核心架构
理解架构是用好框架的前提。LangChain4j的架构设计遵循分层原则,从下到上可以分为四层。
2.1 架构层次
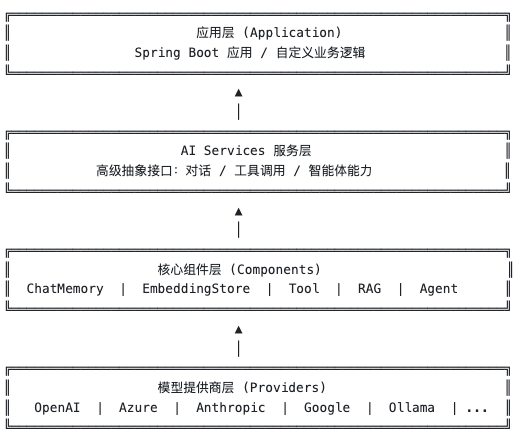 2.2 模型提供商层
2.2 模型提供商层
这一层负责对接各种大模型API。LangChain4j目前支持超过20种模型提供商,包括:
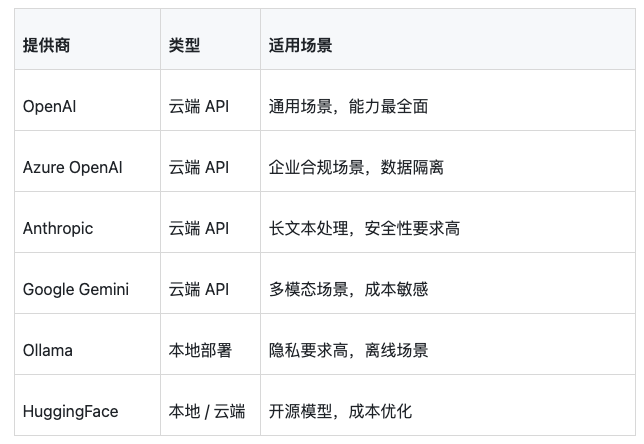
每一层的设计都是接口先行,实现解耦。比如你今天用OpenAI,明天想换成本地Ollama,只需要替换依赖和配置,业务代码完全不用动。
2.3 核心组件层
这一层是框架的精华所在,提供了构建AI应用需要的各种"积木":
ChatLanguageModel:对话模型的核心接口,负责与大模型通信。
ChatMemory:对话记忆管理,支持滑动窗口、摘要等策略。
EmbeddingModel:文本向量化,用于语义检索。
EmbeddingStore:向量存储接口,支持内存、Pinecone、Milvus、Redis等多种后端。
Tool:工具定义,让大模型能够调用外部能力。
ContentRetriever:内容检索器,RAG的核心组件。
Agent:智能体抽象,支持ReAct、Plan-and-Execute等模式。
2.4 AI Services层
这一层是框架提供的"语法糖",让开发者用最少的代码实现常见功能。你只需要定义一个Java接口,加上注解,框架自动生成实现。
interface Assistant {
@SystemMessage("你是一个专业的客服助手")
String chat(@UserMessage String userMessage);
}框架会自动处理:消息组装、模型调用、记忆管理、工具调用等所有细节。
三、LangChain4j核心能力详解
3.1 对话能力
最基础的能力是对话。LangChain4j支持同步和流式两种调用方式。
同步调用示例:
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName("gpt-4o")
.build();
String response = model.generate("你好,请介绍一下自己");流式调用示例:
model.generate("讲一个故事", new StreamingResponseHandler<AiMessage>() {
@Override
public void onNext(String token) {
System.out.print(token); // 实时输出每个token
}
@Override
public void onComplete(Response<AiMessage> response) {
System.out.println("\n[完成]");
}
});流式调用对于提升用户体验非常重要,用户不需要等待模型完整生成,就能看到逐字输出的效果。
3.2 对话记忆
多轮对话中,记忆管理是个技术活。直接把所有历史对话塞给模型,上下文会爆炸;完全不记历史,对话又会断片。
LangChain4j提供了几种记忆策略:
MessageWindowChatMemory:滑动窗口,保留最近N条消息。适合短对话场景。
ChatMemory memory = MessageWindowChatMemory.withMaxMessages(10);TokenWindowChatMemory:按Token数量限制,保留最近的Token。更精确地控制上下文长度。
ChatMemory memory = TokenWindowChatMemory.withMaxTokens(2000, new OpenAiTokenizer());自定义策略:可以实现ChatMemory接口,按需定制。比如按时间衰减、按主题分组等。
实际项目中,我发现TokenWindowChatMemory用得最多。因为不同消息的长度差异很大,按消息数量限制不够精确。
3.3 Function Call(工具调用)
这是让大模型"动手"的关键能力。通过工具调用,模型可以查询数据库、调用API、执行计算等。
定义工具:
class WeatherTools {
@Tool("查询指定城市的当前天气")
public String getWeather(@P("城市名称") String city) {
// 实际调用天气API
return String.format("%s今天晴,温度25°C", city);
}
@Tool("计算两个数的和")
public int add(@P("第一个数") int a, @P("第二个数") int b) {
return a + b;
}
}在AI Services中使用工具:
interface Assistant {
String chat(@UserMessage String userMessage);
}
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.tools(new WeatherTools())
.build();
// 用户问:北京今天天气怎么样?小明和小红年龄分别是10岁和12岁,他们一共多大?
// 模型会自动判断需要调用getWeather和add两个工具
String response = assistant.chat("北京今天天气怎么样?小明和小红年龄分别是10岁和12岁,他们一共多大?");框架会自动处理:解析用户意图、选择工具、执行工具、将结果返回给模型、生成最终回复。整个过程对开发者透明。
3.4 MCP协议支持
MCP(Model Context Protocol)是Anthropic推出的开放协议,用于标准化大模型与外部工具的交互。LangChain4j在近期版本中已经原生支持MCP。
为什么MCP很重要?
之前每个框架都定义自己的工具接口,工具无法跨框架复用。有了MCP,一个工具可以被LangChain4j、LangChain Python、Claude Desktop等多种客户端使用。
LangChain4j集成MCP:
// 通过MCP服务器提供工具
McpTransport transport = StdioMcpTransport.builder()
.command(List.of("npx", "-y", "@modelcontextprotocol/server-filesystem", "/path/to/allowed/dir"))
.build();
McpClient mcpClient = McpClient.builder()
.transport(transport)
.build();
List<Tool> tools = mcpClient.listTools(); // 从MCP服务器获取工具
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.tools(tools) // 直接使用MCP工具
.build();目前MCP生态已经有大量现成的服务器实现,包括:文件系统操作、数据库查询、GitHub API、Slack集成等。开箱即用,大大减少了开发工作量。
四、LangChain4j实战应用
4.1 Spring Boot整合
LangChain4j提供了官方的Spring Boot Starter,整合过程非常丝滑。
添加依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>最新版本</version>
</dependency>配置文件:
langchain4j:
open-ai:
chat-model:
api-key: ${OPENAI_API_KEY}
model-name: gpt-4o
temperature: 0.7
max-tokens: 2000定义AI服务:
interface CustomerServiceAssistant {
@SystemMessage("""
你是一个专业的电商客服助手。
请用友好、专业的语气回答用户问题。
如果不确定答案,请诚实地告诉用户。
""")
String chat(@MemoryId String conversationId, @UserMessage String userMessage);
}注入并使用:
@Service
public class ChatService {
private final CustomerServiceAssistant assistant;
public ChatService(CustomerServiceAssistant assistant) {
this.assistant = assistant;
}
public String handleUserMessage(String sessionId, String message) {
return assistant.chat(sessionId, message);
}
}框架会自动管理每个会话的记忆,你不需要自己处理上下文存储和检索。
4.2 RAG检索增强生成
RAG是让大模型"知道"私有数据的关键技术。典型流程是:用户提问 → 从知识库检索相关内容 → 把检索结果作为上下文 → 模型基于上下文回答。
文档向量化与存储:
// 使用内存向量库(生产环境建议用Milvus、Pinecone等)
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// 向量化并存储文档
DocumentSplitter splitter = new DocumentSplitters.recursiveDocumentSplitter(500, 50);
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/path/to/docs");
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.build();
for (Document doc : documents) {
List<TextSegment> segments = splitter.split(doc);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings, segments);
}构建RAG对话:
interface RAGAssistant {
String chat(@UserMessage String userMessage);
}
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3) // 检索最相关的3个片段
.minScore(0.7) // 相似度阈值
.build();
RAGAssistant assistant = AiServices.builder(RAGAssistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.build();
String answer = assistant.chat("公司的年假政策是什么?");实际项目中,知识库的更新、增量同步、多模态文档处理(PDF、图片、视频)是需要重点考虑的问题。建议使用专业的文档处理管道,而不是简单的文件加载。
4.3 智能体开发
智能体(Agent)是能够自主规划、执行任务的AI系统。LangChain4j支持多种智能体模式。
ReAct模式智能体:
ReAct(Reasoning + Acting)是最经典的智能体模式,模型会交替进行思考和行动。
class CalculatorTools {
@Tool("执行数学计算")
public double calculate(String expression) {
return new ScriptEngineManager()
.getEngineByName("js")
.eval(expression);
}
}
AgentService agentService = AiServices.builder(AgentService.class)
.chatLanguageModel(model)
.tools(new CalculatorTools())
.build();
// 模型会自动:1. 分析问题 → 2. 制定计划 → 3. 调用工具 → 4. 整合结果
String result = agentService.execute("计算:(15 + 27) * 3 - 100 / 4 的结果");自定义智能体:
对于复杂场景,可以实现自定义智能体:
public class CustomAgent {
private final ChatLanguageModel model;
private final List<Tool> tools;
public AgentResult execute(String goal) {
// 1. 分解任务
List<String> subtasks = decomposeGoal(goal);
// 2. 顺序或并行执行子任务
List<AgentResult> results = new ArrayList<>();
for (String subtask : subtasks) {
String action = planAction(subtask);
Object output = executeAction(action);
results.add(new AgentResult(subtask, output));
}
// 3. 整合结果
return synthesizeResults(results);
}
private List<String> decomposeGoal(String goal) {
String prompt = "将以下目标分解为可执行的子任务:" + goal;
return Arrays.asList(model.generate(prompt).split("\n"));
}
// ... 其他方法
}4.4 多智能体协作
对于复杂任务,单个智能体往往力不从心。多智能体协作通过角色分工和专业协同来解决问题。
角色分工模式:
// 研究员智能体
interface ResearcherAgent {
@SystemMessage("你是一个专业的研究员,负责收集和分析信息")
String research(String topic);
}
// 分析师智能体
interface AnalystAgent {
@SystemMessage("你是一个专业的分析师,负责评估和分析数据")
String analyze(String data);
}
// 写作者智能体
interface WriterAgent {
@SystemMessage("你是一个专业的写作者,负责组织和输出内容")
String write(String research, String analysis);
}
// 编排器
@Service
public class MultiAgentOrchestrator {
private final ResearcherAgent researcher;
private final AnalystAgent analyst;
private final WriterAgent writer;
public String executeTask(String topic) {
// 1. 研究员收集信息
String research = researcher.research(topic);
// 2. 分析师分析数据
String analysis = analyst.analyze(research);
// 3. 写作者整合输出
return writer.write(research, analysis);
}
}分层协作模式:
对于更复杂的场景,可以设计层级化的智能体结构:
// 主控制器智能体
interface SupervisorAgent {
@SystemMessage("""
你是项目主管,负责:
1. 理解用户需求
2. 分解任务
3. 分配给合适的专家
4. 整合结果
""")
String supervise(@UserMessage String task);
}
// 专家智能体池
class ExpertPool {
private Map<String, Object> experts; // 编程专家、设计专家、测试专家等
public Object callExpert(String expertise, String task) {
// 根据专长调用对应智能体
return experts.get(expertise).execute(task);
}
}实际应用中,智能体之间的通信机制、状态同步、冲突解决都是需要仔细设计的地方。LangChain4j提供了基础能力,但编排逻辑需要根据业务场景定制。
五、最佳实践与踩坑经验
在过去一年的LangChain4j实战中,我总结了一些经验和教训。
5.1 模型选择策略
不要迷信最强模型。 GPT-4o确实强大,但成本也高。对于简单任务,GPT-3.5-turbo或者Ollama上的开源模型完全够用。
我通常采用分层策略:
- 简单分类、提取任务 → 小模型
- 复杂推理、工具调用 → 中等模型
- 关键决策、代码生成 → 大模型
5.2 记忆管理的坑
问题:一开始我直接使用MessageWindowChatMemory保留20条消息,结果用户反馈"助手会忘记之前的约定"。
原因:20条消息不等于20轮对话,一条包含长文档的消息可能就占满了窗口。
解决:改用TokenWindowChatMemory,并设置合理的Token上限(比如4000)。同时在业务层做重要信息的持久化,而不是完全依赖框架记忆。
5.3 RAG效果优化
简单做了向量化检索,效果往往不理想。几个优化点:
文档切片策略:按固定字符数切分,会把相关内容截断。建议使用语义切片或按段落/标题切分。
检索增强:单用向量检索召回率有限。可以结合关键词检索(BM25)做混合检索。
重排序:检索出候选后,用Cross-Encoder模型做重排序,显著提升相关性。
元数据过滤:按时间、分类、作者等元数据过滤,提高检索精度。
5.4 工具调用稳定性
问题:模型有时候会"幻觉",调用不存在的工具或传递错误参数。
解决:
1. 工具描述要清晰具体,包含参数格式说明
2. 添加参数校验,在工具内部做边界检查
3. 对于关键工具,做两层调用:先让模型输出JSON参数,人工确认后再执行
5.5 异常处理
大模型调用可能失败的原因很多:API超时、Token超限、内容被过滤等。建议在关键路径做降级处理:
String response;
try {
response = model.generate(prompt);
} catch (RateLimitException e) {
// 限流时切换到备用模型
response = fallbackModel.generate(prompt);
} catch (ContentFilterException e) {
response = "抱歉,您的问题触发了内容安全策略";
} catch (Exception e) {
log.error("模型调用失败", e);
response = "系统暂时繁忙,请稍后再试";
}5.6 成本控制
Token消耗很容易超预期。几个建议:
- 开发测试阶段使用本地模型(Ollama)
- 生产环境做Token监控和预警
- 合理设置max-tokens,避免模型无限输出
- 缓存常见问题的回复
六、LangChain4j vs 其他框架
横向对比一下Java生态中其他选择:
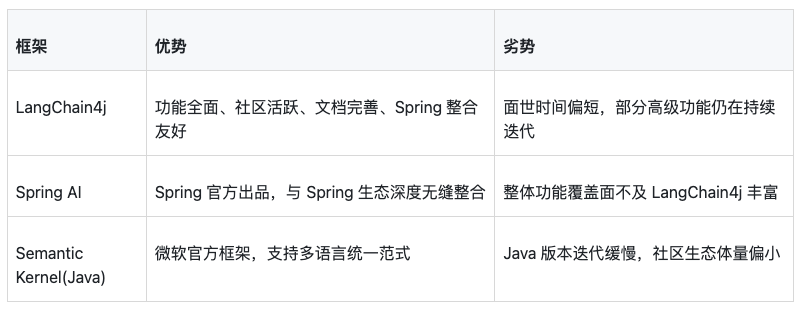
如果是新项目,我的建议是:重度依赖Spring生态的选Spring AI,功能需求全面的选LangChain4j。
Spring AI Alibaba实战指南:阿里云大模型应用的Java开发捷径
传送门:https://xpbyte.cn/archives/spring-ai-alibaba-java-guide
七、常见问题
Q1:LangChain4j支持哪些大模型?
LangChain4j支持几乎所有主流大模型:OpenAI(GPT系列)、Azure OpenAI、Anthropic Claude、Google Gemini、AWS Bedrock、Ollama(本地部署)、HuggingFace等20+种。切换模型只需更换配置。
Q2:LangChain4j和Spring AI该选哪个?
如果项目重度依赖Spring生态,且功能需求简单,Spring AI集成更原生。如果需要更全面的功能(复杂RAG、多智能体、MCP协议等),LangChain4j更合适。两者也可以混用,Spring AI负责简单场景,LangChain4j负责复杂场景。
Q3:RAG效果不好怎么优化?
从三个方向优化:1)文档预处理(切片策略、格式清洗);2)检索策略(混合检索、重排序、元数据过滤);3)提示词工程(让模型更好地利用检索结果)。也可以考虑GraphRAG等更高级的方案。
Q4:如何处理大模型的幻觉问题?
几个策略:1)RAG检索相关事实作为约束;2)在System Prompt中明确要求"不知道就说不知道";3)对于关键信息,做事实核查;4)使用思维链(Chain of Thought)引导模型逐步推理。
Q5:LangChain4j适合生产环境吗?
适合。LangChain4j已经有很多生产案例,包括企业知识库、智能客服、代码助手等场景。需要注意:做好监控、降级、成本控制,选择稳定的模型版本。
Q6:本地部署大模型推荐哪个?
资源充足(24GB+显存):Llama 3.1 8B、Qwen 2.5 7B
资源有限(8-16GB显存):Phi-3 Mini、Gemma 2 2B
仅CPU运行:考虑量化版本或云端API
使用Ollama部署非常简单ollama run llama3.1 即可。
八、总结
LangChain4j为Java开发者打开了一扇通往大模型应用开发的大门。它不是一个简单的API封装,而是一套完整的开发框架,从模型接入到智能体编排,都有成熟的解决方案。
对于已经在Java生态深耕的团队,LangChain4j让大模型应用落地变得可触及。不需要重新学习Python生态,不需要改变现有的技术栈和部署流程,就可以构建功能完善的AI应用。
当然,框架只是工具。真正用好它,还需要理解大模型的能力边界,掌握Prompt Engineering,熟悉RAG和Agent的设计模式。这些内容本文只是点到为止,后续有机会再深入展开。
如果你正在评估或使用LangChain4j,欢迎交流经验。
---
参考资料:
- [LangChain4j官方文档](https://docs.langchain4j.dev/)
- [LangChain4j GitHub仓库](https://github.com/langchain4j/langchain4j)
- [LangChain4j MCP集成文档](https://docs.langchain4j.dev/tutorials/mcp)
- [LangChain4j AI Services文档](https://docs.langchain4j.dev/tutorials/ai-services)
- [LangChain4j示例代码库](https://github.com/langchain4j/langchain4j-examples)