摘要:本文深入解析Spring AI Alibaba框架,涵盖核心架构、通义千问模型接入、Spring Boot整合实战,以及对话记忆、Function Call、RAG检索增强、智能体开发等关键能力。适合需要快速接入阿里云AI服务的Java开发者。
前言:为什么选择Spring AI Alibaba
去年我们团队有个紧急需求:要在三天内为一个现有的Spring Boot电商系统加上智能客服功能。当时评估了几个方案——直接调用阿里云DashScope API、用LangChain4j、或者用Spring AI Alibaba。
最终我们选了Spring AI Alibaba,原因很简单:项目本来就是Spring Boot架构,用官方提供的Starter,两小时就把基础对话功能跑通了。更重要的是,后续的RAG、工具调用、智能体等功能,都有现成的抽象和示例。
如果你也在寻找一条快速、稳妥的阿里云大模型接入路径,这篇文章会帮你理清Spring AI Alibaba的核心概念,并通过实战代码展示如何落地。
一、Spring AI Alibaba是什么
Spring AI Alibaba是阿里云官方推出的Spring AI扩展实现,专门用于接入阿里云的AI服务。它不是独立框架,而是Spring AI生态的一部分,遵循Spring AI的统一抽象规范。
1.1 核心定位
用一句话概括:Spring AI Alibaba让Java开发者用Spring的方式,无缝调用阿里云的通义千问、通义万相等AI服务。它解决的是这三个核心问题:
模型接入简化 —— 不需要研究DashScope API文档,不需要处理签名认证、请求封装等细节,配置好API Key就能用。
能力抽象统一 —— 对话、嵌入、图像生成、语音识别等能力都有统一的接口。理论上换成其他模型提供商,业务代码不用大改。
Spring生态融合 —— 自动配置、依赖注入、配置管理、健康检查,这些Spring Boot开发者熟悉的东西全都支持。
1.2 与直接调用DashScope API的区别
有些开发者会问:直接用阿里云的DashScope SDK不就行了?为什么要用Spring AI Alibaba?这个问题我在项目中也思考过。直接调用SDK确实可行,但会遇到这些麻烦:
认证复杂:DashScope需要处理API Key、签名、请求头等,代码冗余
响应处理繁琐:流式响应、错误重试、超时控制都要自己写
能力扩展困难:想加RAG、记忆、工具调用,得自己设计架构
切换成本高:如果以后要换模型(比如用本地Ollama),代码改动量大
Spring AI Alibaba把这些都封装好了,你只需要关注业务逻辑。
1.3 支持的模型和服务
Spring AI Alibaba目前支持阿里云的以下AI服务:
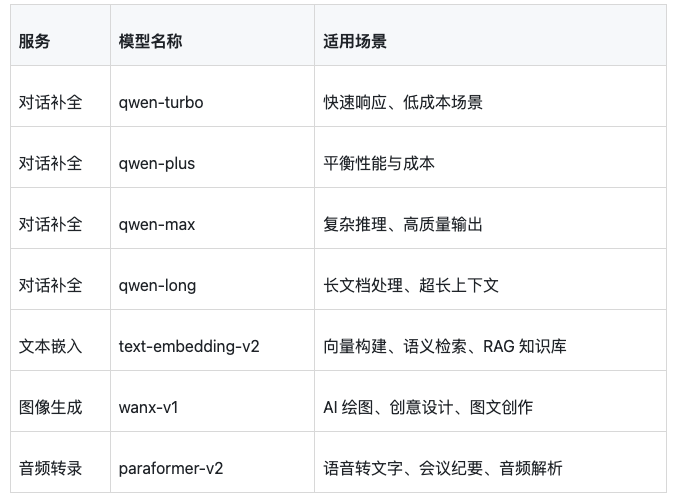
对于大多数企业应用,qwen-plus是性价比最好的选择。它响应快、质量高,而且价格比qwen-max低很多。
二、Spring AI Alibaba核心架构
理解架构是用好框架的第一步。Spring AI Alibaba建立在Spring AI框架之上,整体架构可以分为四层。
2.1 架构层次图
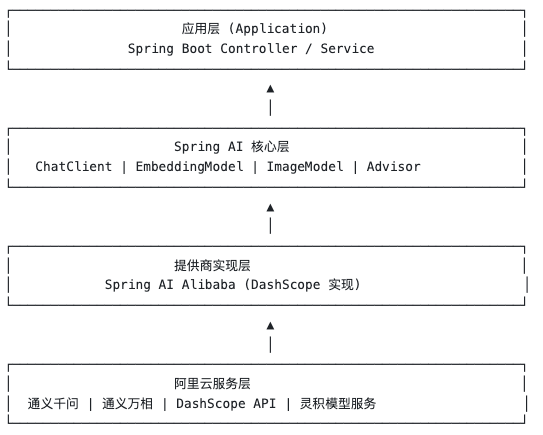
2.2 Spring AI核心层
这一层是Spring AI框架提供的通用抽象,所有提供商都遵循这些接口:
ChatClient:对话的核心入口,提供流畅的API设计。支持同步调用、流式调用、多轮对话、系统提示等功能。
EmbeddingModel:文本向量化接口,用于将文本转换为向量。这是RAG、语义检索的基础。
ImageModel:图像生成接口,调用AI模型生成图片。
AudioTranscriptionModel:语音转文字接口。
Advisor:拦截器模式,可以在请求前后做处理。比如添加记忆、注入检索结果、记录日志等。
2.3 Spring AI Alibaba实现层
这一层是对Spring AI接口的具体实现,核心是对接DashScope API:
DashScopeChatModel:实现了ChatClient需要的ChatModel接口,处理与通义千问的通信。
DashScopeEmbeddingModel:实现文本嵌入,支持阿里云的text-embedding模型。
DashScopeImageModel:调用通义万相进行图像生成。
DashScopeAudioTranscriptionModel:调用paraformer进行语音转录。
所有实现都封装了:认证、请求构建、响应解析、错误处理、重试逻辑。开发者完全不用关心这些细节。
2.4 阿里云服务层
最底层是阿里云的实际AI服务。通义千问、通义万相、DashScope API、灵积模型服务都在这里。开发者需要知道的只有一个概念:DashScope。DashScope是阿里云AI服务的统一入口,所有模型调用都通过DashScope API完成。你需要:
1. 注册阿里云账号
2. 开通DashScope服务
3. 创建API-KEY
4. 在Spring Boot配置中填入API-KEY
剩下的工作,Spring AI Alibaba会自动处理。
三、Spring AI Alibaba核心能力详解
3.1 对话能力
对话是最基础也是最常用的能力。Spring AI提供了两种使用方式:低级API(ChatModel)和高级API(ChatClient)。
ChatModel直接调用:
@Service
public class ChatService {
private final ChatModel chatModel;
public ChatService(ChatModel chatModel) {
this.chatModel = chatModel;
}
public String chat(String userMessage) {
Prompt prompt = new Prompt(userMessage);
ChatResponse response = chatModel.call(prompt);
return response.getResult().getOutput().getContent();
}
}这种方式适合简单场景,但对于复杂的多轮对话、系统提示、参数控制等,代码会比较冗长。
ChatClient流畅API:
@Service
public class SmartChatService {
private final ChatClient chatClient;
public SmartChatService(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("你是一个专业的电商客服助手,回答要简洁友好")
.defaultOptions(ChatOptionsBuilder.builder()
.withModel("qwen-plus")
.withTemperature(0.7)
.build())
.build();
}
public String chat(String userMessage) {
return chatClient.prompt()
.user(userMessage)
.call()
.content();
}
// 流式调用
public Flux<String> chatStream(String userMessage) {
return chatClient.prompt()
.user(userMessage)
.stream()
.content();
}
}ChatClient的设计非常优雅,使用Builder模式,配置一目了然。实际项目中,我几乎都用ChatClient,除非有非常特殊的需求。
多轮对话:
public String multiTurnChat(List<Message> history, String newMessage) {
ChatResponse response = chatClient.prompt()
.messages(history) // 历史对话
.user(newMessage) // 新消息
.call();
return response.getResult().getOutput().getContent();
}消息历史可以自己维护,也可以用后面讲到的Advisor自动管理。
3.2 对话记忆
多轮对话中,记忆管理至关重要。Spring AI通过Advisor模式实现记忆能力。
使用ChatMemoryAdvisor:
@Service
public class MemoryChatService {
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public MemoryChatService(ChatClient.Builder builder) {
// 创建消息窗口记忆,保留最近10条
this.chatMemory = new MessageWindowChatMemory(10);
this.chatClient = builder
.defaultSystem("你是一个智能助手")
.defaultAdvisors(new ChatMemoryAdvisor(chatMemory))
.build();
}
public String chat(String sessionId, String userMessage) {
return chatClient.prompt()
.user(userMessage)
.advisors(advisorSpec -> advisorSpec
.param(ChatMemoryAdvisor.CONVERSATION_ID, sessionId))
.call()
.content();
}
}关键CONVERSATION_ID参数,用它区分不同用户的会话。框架会自动管理每个会话的历史消息,在调用模型时自动注入上下文。
记忆策略选择:

项目中我习惯用TokenWindowChatMemory,因为不同消息长度差异大,按消息数限制不够精确。
3.3 Function Call(工具调用)
这是让大模型"动手干活"的核心能力。通过定义工具,模型可以调用外部API、查询数据库、执行计算。
定义工具函数:
@Component
public class OrderTools {
private final OrderService orderService;
public OrderTools(OrderService orderService) {
this.orderService = orderService;
}
@Tool(description = "查询用户最近的订单信息")
public OrderInfo getRecentOrder(@ToolParam(description = "用户ID") String userId) {
return orderService.getRecentOrder(userId);
}
@Tool(description = "查询订单物流状态")
public LogisticsStatus getLogistics(@ToolParam(description = "订单号") String orderId) {
return orderService.getLogistics(orderId);
}
@Tool(description = "创建新订单")
public String createOrder(@ToolParam(description = "商品ID") String productId,
@ToolParam(description = "数量") int quantity) {
return orderService.createOrder(productId, quantity);
}
}工具方法的注解要清晰具体,因为模型会根据描述来决定是否调用。
在ChatClient中注册工具:
@Service
public class AgentChatService {
private final ChatClient chatClient;
public AgentChatService(ChatClient.Builder builder, OrderTools orderTools) {
this.chatClient = builder
.defaultSystem("你是电商订单助手,可以帮助用户查询和管理订单")
.defaultFunctions(orderTools) // 注册工具
.build();
}
public String chat(String userMessage) {
return chatClient.prompt()
.user(userMessage)
.functions("getRecentOrder", "getLogistics", "createOrder") // 可动态指定可用工具
.call()
.content();
}
}当用户问"我最近的订单到哪了",模型会自动:
1. 调用getRecentOrder获取订单号
2. 调用getLogistics查询物流
3. 整合结果返回给用户
整个过程对开发者透明,框架会处理意图识别、参数提取、工具执行、结果整合。
3.4 MCP协议支持
MCP(Model Context Protocol)是Anthropic推出的开放协议,用于标准化大模型与工具的交互。Spring AI Alibaba也支持MCP。
为什么MCP重要:
之前的工具定义是框架特定的,LangChain的工具不能给Spring AI用,反过来也一样。MCP打破了这种壁垒,一个MCP服务器可以被多种客户端调用。
配置MCP客户端:
@Configuration
public class McpConfig {
@Bean
public McpClient mcpClient() {
return McpClient.sync(
StdioClientTransport.builder()
.command("npx", "-y", "@anthropic/mcp-server-filesystem", "/data")
.build()
);
}
@Bean
public List<FunctionCallback> mcpTools(McpClient mcpClient) {
// 从MCP服务器获取工具
return mcpClient.listTools()
.stream()
.map(tool -> McpFunctionCallback.builder()
.mcpClient(mcpClient)
.tool(tool)
.build())
.toList();
}
}现在你可以直接使用MCP生态中现成的服务器:文件系统、数据库查询、GitHub操作、Slack通知等,不需要自己写实现。
3.5 RAG检索增强生成
RAG是让大模型"知道"企业私有数据的关键技术。Spring AI Alibaba提供了完整的RAG支持。
向量化文档:
@Service
public class DocumentEmbeddingService {
private final EmbeddingModel embeddingModel;
private final VectorStore vectorStore;
public DocumentEmbeddingService(EmbeddingModel embeddingModel,
VectorStore vectorStore) {
this.embeddingModel = embeddingModel;
this.vectorStore = vectorStore; // 可以是Redis、Milvus等
}
public void embedDocuments(List<String> documents) {
List<Document> docList = documents.stream()
.map(content -> new Document(content))
.toList();
// 批量向量化并存储
vectorStore.add(docList);
}
}构建RAG对话:
@Service
public class RAGChatService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
public RAGChatService(ChatClient.Builder builder,
VectorStore vectorStore,
EmbeddingModel embeddingModel) {
this.vectorStore = vectorStore;
this.embeddingModel = embeddingModel;
this.chatClient = builder
.defaultSystem("""
你是企业的知识库助手。
请根据提供的上下文回答用户问题。
如果上下文中没有相关信息,请诚实地说不知道。
""")
.build();
}
public String chat(String userMessage) {
// 1. 向量化用户问题
List<Double> queryEmbedding = embeddingModel.embed(userMessage);
// 2. 检索相关文档
List<Document> relevantDocs = vectorStore.similaritySearch(
SearchRequest.query(userMessage)
.withTopK(3)
.withSimilarityThreshold(0.7)
);
// 3. 构建包含上下文的提示
String context = relevantDocs.stream()
.map(doc -> doc.getContent())
.join("\n\n---\n\n");
return chatClient.prompt()
.system("参考以下上下文回答问题:\n" + context)
.user(userMessage)
.call()
.content();
}
}实际项目中,RAG效果优化是个持续迭代的过程。建议关注:
- 文档切片策略(语义切分优于固定长度切分)
- 混合检索(向量+关键词)
- 重排序(Cross-Encoder精排)
- 元数据过滤(按分类、时间筛选)
3.6 智能体开发
智能体是能够自主规划、调用工具、执行任务的AI系统。Spring AI Alibaba支持构建智能体应用。
单智能体实现:
@Service
public class OrderAgentService {
private final ChatClient chatClient;
public OrderAgentService(ChatClient.Builder builder,
OrderTools orderTools,
InventoryTools inventoryTools) {
this.chatClient = builder
.defaultSystem("""
你是智能订单处理助手。
当用户需要处理订单相关任务时,请:
1. 分析任务需求
2. 选择合适的工具
3. 执行操作
4. 整合结果回复用户
""")
.defaultFunctions(orderTools, inventoryTools)
.build();
}
public String execute(String task) {
return chatClient.prompt()
.user(task)
.call()
.content();
}
}用户输入:"帮我查一下用户U001最近的订单,如果还没发货就取消它"。智能体会自动:
1. 调用getRecentOrder("U001")获取订单
2. 判断发货状态
3. 如果未发货,调用cancelOrder
4. 整合结果回复
带反思的智能体:
对于复杂任务,可以设计反思循环:
@Service
public class ReflectiveAgentService {
private final ChatClient executorClient;
private final ChatClient reflectorClient;
public String executeWithReflection(String goal) {
String result = executorClient.prompt()
.user("执行任务:" + goal)
.call()
.content();
// 反思是否达成目标
String reflection = reflectorClient.prompt()
.user("""
原始目标:%s
执行结果:%s
请评估:任务是否完成?如果未完成,还需要什么操作?
""".formatted(goal, result))
.call()
.content();
// 如果反思发现未完成,继续执行
if (reflection.contains("需要继续")) {
return executeWithReflection(reflection);
}
return result;
}
}3.7 多智能体协作
复杂场景中,单个智能体能力有限。多智能体通过角色分工、协同合作来解决问题。
角色分工模式:
// 研究员智能体
@Service
public class ResearcherAgent {
private final ChatClient chatClient;
public ResearcherAgent(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("你是专业研究员,负责收集和分析信息")
.build();
}
public String research(String topic) {
return chatClient.prompt()
.user("请收集关于以下主题的信息:" + topic)
.call()
.content();
}
}
// 分析师智能体
@Service
public class AnalystAgent {
private final ChatClient chatClient;
public AnalystAgent(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("你是专业分析师,负责评估数据并给出见解")
.build();
}
public String analyze(String data) {
return chatClient.prompt()
.user("请分析以下数据:" + data)
.call()
.content();
}
}
// 编排器
@Service
public class MultiAgentOrchestrator {
private final ResearcherAgent researcher;
private final AnalystAgent analyst;
private final WriterAgent writer;
public String execute(String topic) {
// 1. 研究员收集信息
String researchResult = researcher.research(topic);
// 2. 分析师分析数据
String analysisResult = analyst.analyze(researchResult);
// 3. 汇报者整合输出
return writer.write(researchResult, analysisResult);
}
}层级协作模式:
// 主控制器智能体
@Service
public class SupervisorAgent {
private final ChatClient chatClient;
private final ExpertPool expertPool;
public String supervise(String task) {
// 1. 分解任务
String plan = chatClient.prompt()
.user("将以下任务分解为子任务:" + task)
.call()
.content();
// 2. 分配给专家
List<String> subtasks = parseSubtasks(plan);
List<String> results = new ArrayList<>();
for (String subtask : subtasks) {
String expertType = determineExpert(subtask);
results.add(expertPool.call(expertType, subtask));
}
// 3. 整合结果
return chatClient.prompt()
.user("""
原始任务:%s
子任务执行结果:%s
请整合以上结果,给出最终答案。
""".formatted(task, results))
.call()
.content();
}
}四、Spring Boot整合实战
4.1 项目搭建
添加依赖:
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version>
<scope>compile</scope>
</dependency>
<!-- 如果需要向量存储 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-vector-store</artifactId>
</dependency>配置文件:
spring:
ai:
alibaba:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
chat:
options:
model: qwen-plus
temperature: 0.7
max-tokens: 2000
embedding:
options:
model: text-embedding-v2
vectorstore:
redis:
uri: redis://localhost:6379
index: knowledge-base4.2 完整的智能客服示例
定义AI服务接口:
public interface CustomerServiceAssistant {
String chat(String sessionId, String userMessage);
Flux<String> chatStream(String sessionId, String userMessage);
}实现AI服务:
@Service
public class CustomerServiceAssistantImpl implements CustomerServiceAssistant {
private final ChatClient chatClient;
private final ChatMemory chatMemory;
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
public CustomerServiceAssistantImpl(ChatClient.Builder builder,
VectorStore vectorStore,
EmbeddingModel embeddingModel,
CustomerTools customerTools) {
this.vectorStore = vectorStore;
this.embeddingModel = embeddingModel;
this.chatMemory = new TokenWindowChatMemory(4000);
this.chatClient = builder
.defaultSystem("""
你是专业的电商客服助手。
请友好、准确地回答用户问题。
可以查询订单、产品信息。
如果不确定,请诚实告知。
""")
.defaultAdvisors(
new ChatMemoryAdvisor(chatMemory),
new QuestionAnswerAdvisor(vectorStore)
)
.defaultFunctions(customerTools)
.build();
}
@Override
public String chat(String sessionId, String userMessage) {
return chatClient.prompt()
.user(userMessage)
.advisors(spec -> spec.param(ChatMemoryAdvisor.CONVERSATION_ID, sessionId))
.call()
.content();
}
@Override
public Flux<String> chatStream(String sessionId, String userMessage) {
return chatClient.prompt()
.user(userMessage)
.advisors(spec -> spec.param(ChatMemoryAdvisor.CONVERSATION_ID, sessionId))
.stream()
.content();
}
}Controller层:
@RestController
@RequestMapping("/api/chat")
public class ChatController {
private final CustomerServiceAssistant assistant;
@PostMapping
public ResponseEntity<ChatResponse> chat(@RequestBody ChatRequest request) {
String response = assistant.chat(request.getSessionId(), request.getMessage());
return ResponseEntity.ok(new ChatResponse(response));
}
@PostMapping("/stream")
public Flux<String> chatStream(@RequestBody ChatRequest request) {
return assistant.chatStream(request.getSessionId(), request.getMessage());
}
}4.3 知识库管理
文档导入服务:
@Service
public class KnowledgeBaseService {
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
private final TikaDocumentReader documentReader;
public void importDocuments(String directoryPath) {
List<Resource> resources = loadResources(directoryPath);
for (Resource resource : resources) {
// 读取文档内容
List<Document> documents = documentReader.read(resource);
// 切分文档
List<Document> chunks = new TokenTextSplitter()
.split(documents);
// 向量化存储
vectorStore.add(chunks);
}
}
public void importProductInfo(List<Product> products) {
List<Document> docs = products.stream()
.map(p -> new Document(
"产品:%s,描述:%s,价格:%s".formatted(
p.getName(), p.getDescription(), p.getPrice()),
Map.of("productId", p.getId(), "category", p.getCategory())
))
.toList();
vectorStore.add(docs);
}
}五、最佳实践与经验总结
5.1 模型选择策略
实际项目中,不要一味追求最强模型。我的经验是:
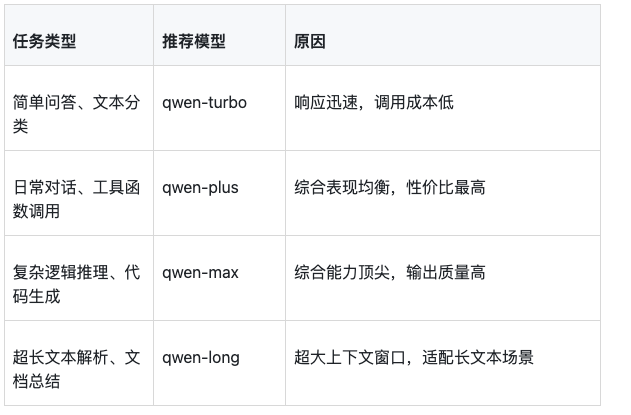
大多数业务场景,qwen-plus就够了。复杂推理场景才考虑qwen-max。
5.2 Token控制
通义千问的Token计算和OpenAI有差异,需要注意:
- 中文Token消耗更高(一个汉字通常是2-3个Token)
- 代码和表格Token消耗大
- 系统提示不要过长,会持续消耗Token
建议在业务层做Token监控:
@Component
public class TokenMonitorAdvisor implements RequestResponseAdvisor {
private final MeterRegistry meterRegistry;
@Override
public AdvisedResponse adviseResponse(AdvisedResponse response, ...) {
ChatResponse chatResponse = response.response();
Usage usage = chatResponse.getMetadata().getUsage();
meterRegistry.counter("ai.tokens.input")
.increment(usage.getPromptTokens());
meterRegistry.counter("ai.tokens.output")
.increment(usage.getGenerationTokens());
return response;
}
}5.3 流式响应处理
用户体验上,流式响应比同步响应好得多。前端实现:
const chatStream = async (message) => {
const response = await fetch('/api/chat/stream', {
method: 'POST',
body: JSON.stringify({ sessionId, message })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
appendToChat(chunk); // 实时显示
}
};后端返回的Flux<String>会逐Token推送,用户看到的是逐渐浮现的文字,而不是等待很久后突然出现一大段。
5.4 错误处理与降级
大模型调用可能失败,需要设计降级策略:
@Service
public class ResilientChatService {
private final ChatClient primaryClient;
private final ChatClient fallbackClient;
public String chat(String message) {
try {
return primaryClient.prompt()
.user(message)
.call()
.content();
} catch (ApiException e) {
log.warn("主模型调用失败,切换备用模型", e);
return fallbackClient.prompt()
.user(message)
.call()
.content();
} catch (ContentFilterException e) {
return "您的问题触发了安全策略,请调整后重试";
} catch (Exception e) {
log.error("模型调用异常", e);
return "系统暂时繁忙,请稍后再试";
}
}
}建议配置备用模型(比如qwen-turbo作为qwen-plus的备用),并在关键路径做熔断和限流。
5.5 RAG效果优化经验
简单接入RAG后,效果往往不理想。几个优化方向:
文档预处理:
- 清理格式噪音(HTML标签、乱码)
- 语义切分优于固定长度切分
- 为每个切片添加元数据(来源、时间、分类)
检索策略:
- 混合检索:向量检索+关键词检索(BM25)
- 多路召回:同时用不同策略召回,再合并
- 重排序:用Cross-Encoder对召回结果精排
提示优化:
- 明确告诉模型"如果上下文没有相关信息就说不知道"
- 引导模型先分析上下文,再回答问题
String systemPrompt = """
你是知识库助手。请遵循以下规则:
1. 先仔细阅读提供的上下文
2. 如果上下文包含答案,基于上下文回答
3. 如果上下文没有相关信息,明确说"根据现有知识库,我无法回答这个问题"
4. 不要编造或推测信息
""";六、Spring AI Alibaba与其他框架对比
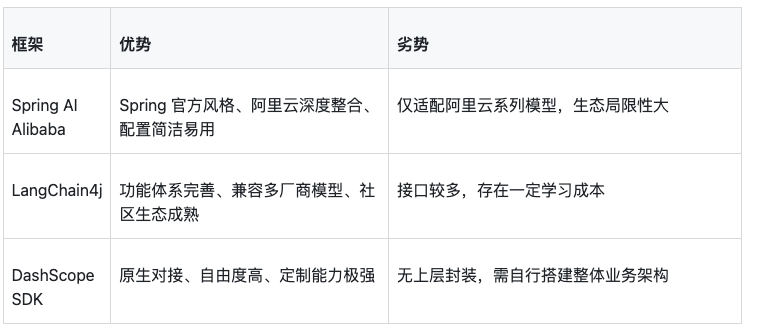
我的建议:
如果项目已经用Spring Boot,且确定使用阿里云的AI服务,Spring AI Alibaba是最省心的选择。如果需要支持多模型提供商或更复杂的Agent编排,LangChain4j更合适。
两者也可以结合使用:Spring AI Alibaba处理阿里云模型调用,LangChain4j处理复杂的Agent逻辑。
LangChain4j实战指南:Java开发者的大模型应用框架深度解析
传送门:https://xpbyte.cn/archives/langchain4j-java-llm-guide
七、常见问题
Q1:如何获取阿里云DashScope API Key?
登录阿里云控制台 → 搜索"DashScope" → 开通服务 → 创建API-KEY。新用户有免费额度,可以先试用。
Q2:通义千问和GPT有什么区别?
都是优秀的对话模型。通义千问的优势:
- 中文理解更好(更适合国内业务)
- 长上下文支持(qwen-long支持超长文档)
- 成本更低(同等能力下价格更优)
- 数据合规(数据在阿里云,不跨境)
Q3:Spring AI Alibaba支持哪些向量存储?
支持Redis、Milvus、Pinecone、PGVector、SimpleMemory等多种后端。Redis用得最多,部署简单,与Spring生态整合好。
Q4:如何处理模型的幻觉问题?
几个策略:
- RAG注入事实约束
- System Prompt要求"不确定就说不知道"
- 关键信息做事实核查
- 对生成内容做人工审核(敏感场景)
Q5:流式响应如何在前端展示?
前端接收SSE流或WebSocket流,逐Token追加显示。Spring WebFlux返回的Flux<String>天然支持流式传输。
Q6:生产环境部署要注意什么?
几点建议:
- 配置熔断和限流(防止API超限)
- 做好Token监控和预警
- 关键路径有降级方案
- 日志脱敏(不要记录敏感对话)
- 配置缓存(常见问题缓存回复)
八、总结
Spring AI Alibaba为Java开发者提供了一条通往阿里云AI服务的"捷径"。它不是简单的API封装,而是完整的Spring风格集成方案,从对话、记忆、工具调用到RAG、智能体,都有成熟的支持。
对于已经在Spring生态深耕的团队,Spring AI Alibaba让大模型应用落地变得可触及。不需要研究复杂的API文档,不需要设计自己的架构抽象,开箱即用。
当然,框架只是起点。真正构建好用的AI应用,还需要理解大模型的能力边界,设计合理的交互流程,持续优化RAG效果,处理各种异常情况。这些是框架帮不了的,需要开发者在实践中积累。
如果你正在评估或使用Spring AI Alibaba,欢迎交流经验。
---
参考资料:
- [Spring AI Alibaba官方文档](https://java2ai.com)
- [阿里云DashScope文档](https://help.aliyun.com/zh/dashscope/)
- [Spring AI官方文档](https://docs.spring.io/spring-ai/reference/)
- [Spring AI Alibaba GitHub](https://github.com/alibaba/spring-ai-alibaba)
- [通义千问模型介绍](https://qwenlm.github.io/)