

摘要:Chroma 是一个面向 AI 应用的开源向量数据库,常用于 RAG、知识库问答、文档检索、Agent 记忆和语义搜索。相比 Milvus、Qdrant、pgvector 这类方案,Chroma 的优势是上手快、API 简单、适合本地开发和初学者理解向量检索完整流程。本文从向量数据库选型讲起,系统介绍 Chroma 的适用场景、实现原理、安装使用、常用语法、metadata 过滤,以及如何在 Java 项目中通过 Spring AI 集成 Chroma 构建一个基础 RAG 检索链路。
写在前面:为什么很多人第一次做 RAG 会选 Chroma
如果你第一次做 RAG,最容易卡住的地方往往不是大模型,而是“知识怎么存、怎么搜”。
一个最小 RAG 系统至少要做几件事:文档 -> 切块 -> Embedding -> 向量存储 -> 相似度检索 -> Prompt -> 大模型回答。 这里的“向量存储”和“相似度检索”,就是向量数据库的主要工作。
Chroma 的定位很清楚:它不是最复杂、最重型的向量数据库,而是一个非常适合 AI 应用开发者快速上手的开源向量数据库。官方文档也把它描述为面向 AI 的开源数据基础设施,内置了启动 RAG 原型需要的基本能力,可以在本机运行,也可以用 client-server 模式连接独立服务。
这正是它适合初学者的原因:
安装简单,
pip install chromadb就能开始。API 直观,核心概念主要是 client、collection、document、embedding、metadata。
本地开发友好,可以先用内存模式或本地持久化模式。
可以自动生成 embedding,也可以接入自己生成好的 embedding。
支持 metadata 过滤,能做基础权限、类型、版本过滤。
生态里有 LangChain、LlamaIndex、Spring AI 等常见框架集成。
如果你只是想理解 RAG 的完整链路,Chroma 比上来就部署一套复杂集群更合适。它能让你把注意力放在文档切块、Embedding、召回质量和 Prompt 组装上,而不是一开始就陷进分片、压缩、扩容和运维细节。
当然,适合入门不等于只能做玩具项目。Chroma 也支持独立服务模式和 Chroma Cloud。但在选型时,仍然要根据数据规模、团队技术栈、线上稳定性、权限隔离、运维能力和成本做判断。
一、向量数据库怎么选:别一上来就问“哪个最好”
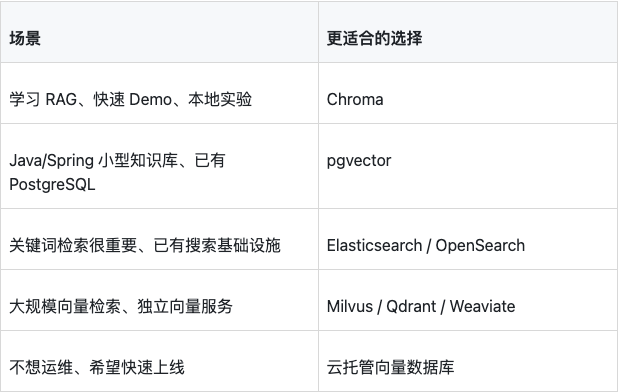
向量数据库没有绝对最好,只有适不适合当前阶段。选型时可以先问五个问题:
第一,数据规模有多大?
如果只是几千到几十万条 chunk,Chroma、pgvector、本地向量库都可以。如果是千万级、亿级向量,并且对召回延迟和扩展性有硬要求,就要认真评估 Milvus、Qdrant、Weaviate、Pinecone、Elasticsearch/OpenSearch 向量检索等更偏生产规模的方案。
第二,团队是不是已经有数据库基础设施?
如果公司已经大量使用 PostgreSQL,且向量数据规模不大,pgvector 可能更容易落地。如果团队已经有 Elasticsearch/OpenSearch,并且关键词检索是强需求,可以考虑在搜索引擎里做向量和关键词混合检索。
第三,RAG 系统是不是还在 Demo 阶段?
如果还在验证产品方向,Chroma 很合适。它能快速跑通“写入文档、向量检索、metadata 过滤、返回结果”这条链路,试错成本低。
第四,线上是否需要复杂权限和多租户隔离?
企业知识库通常要按租户、部门、角色、文档密级、版本、生效时间过滤。向量数据库不仅要能做相似度检索,还要能做可靠 metadata filter。Chroma 支持 metadata 过滤,但复杂权限模型最好在应用层和数据层一起设计,不要只靠 Prompt 约束。
第五,谁来运维?
本地 Chroma 很轻,但生产环境仍然要考虑备份、恢复、监控、访问控制、版本升级、数据迁移。如果团队没有运维资源,托管服务可能比自建更合适。
可以简单总结:
所以 Chroma 的最佳位置是:学习成本低、原型速度快、适合把 RAG 基础链路讲清楚,也适合中小规模知识库的早期实现。
二、Chroma 的核心概念和实现原理
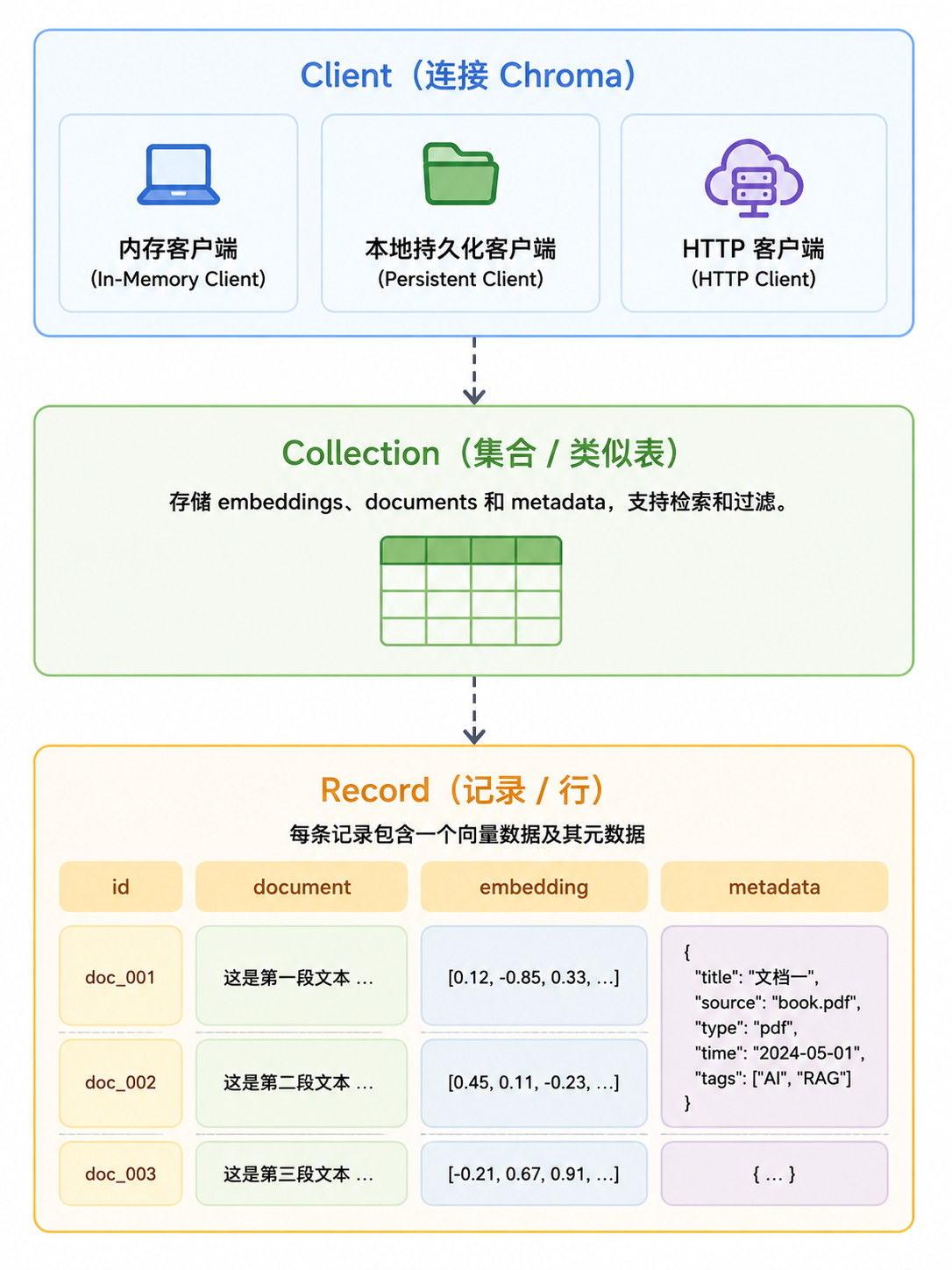
Chroma 的核心概念不多。
最外层是 Client。
Client 用来连接 Chroma。它可以是内存客户端、本地持久化客户端,也可以是连接远程 Chroma 服务的 HTTP Client。
第二层是 Collection。
Collection 可以理解为一组向量数据的集合,类似关系型数据库里的表,但它面向的是 embedding、document 和 metadata。官方文档里也强调,Collection 用来存储 embeddings、documents 和附加 metadata,并支持检索和过滤。
第三层是 Record。
一条典型记录可以理解为:
{
"id": "refund-policy#chunk-001",
"document": "订单进入结算流程后,不支持原路退款,需要走人工退款流程。",
"embedding": [0.013, -0.082, 0.194],
"metadata": {
"doc_type": "policy",
"product": "payment",
"version": "2026",
"permission": "support"
}
}
Chroma 的检索过程大致是:
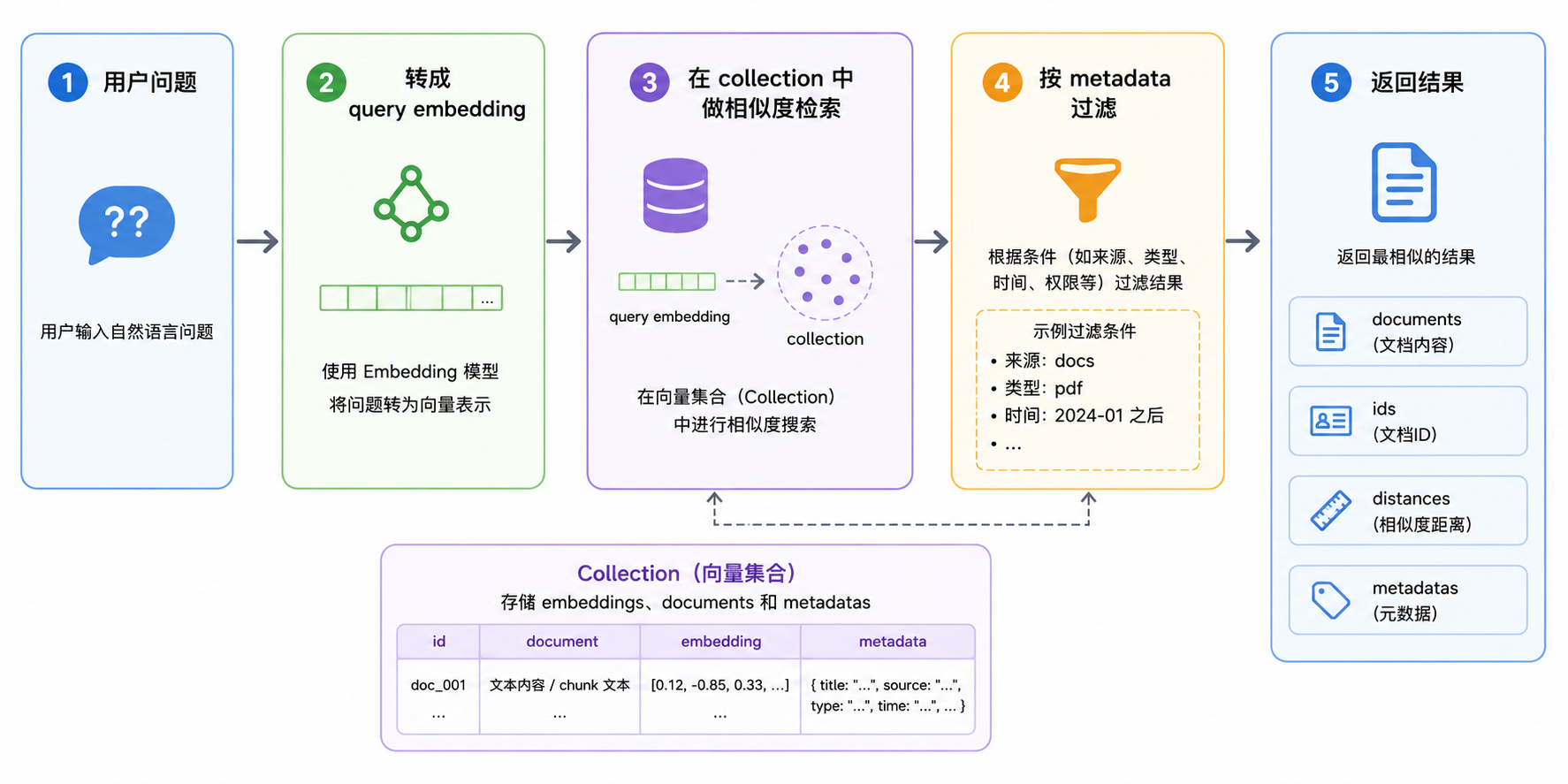
这里有几个点需要初学者特别注意。
第一,Chroma 可以帮你自动生成 embedding,也可以接收你提前算好的 embedding。
如果你只传 documents,Chroma 会使用 collection 配置的 embedding function 生成向量;如果你已经在外部用自己的模型算好了向量,也可以把 embeddings 一起传进去。官方文档明确说明,添加数据时至少要提供 documents、embeddings 二者之一。
第二,id 必须唯一。
Chroma 的 add 要求每条记录有唯一字符串 ID。如果你重复添加同一个 ID,行为和更新不是一回事。工程里更推荐把文档 ID、版本号、chunk 序号拼进 ID,例如:
doc_2026_refund_policy:v1:chunk_0001第三,metadata 很重要。
向量检索只能判断“语义像不像”,不能判断“这个用户能不能看”“这份文档是否过期”“是不是当前产品线”。这些问题要靠 metadata 和业务权限系统解决。
第四,Chroma 不等于完整 RAG 系统。
Chroma 解决的是向量存储和检索问题。文档解析、切块、Embedding 模型选择、Rerank、Prompt 组装、引用生成、效果评估,仍然需要应用层处理。
三、Chroma 安装与启动:本地模式、持久化模式和服务模式
Chroma 的 Python 安装很直接:(依赖python环境,推荐Python 3.10)
pip install chromadb验证:(进入phthon环境)
python import chromadb
print(chromadb.__version__)安装后,需要进入进入python控制台,通过Python脚本中操作数据库。
方式一:内存客户端 (EphemeralClient):数据仅在内存中,程序退出即销毁。
import chromadb
client = chromadb.Client()
collection = client.get_or_create_collection(name="rag_demo")这种方式适合快速试 API,但数据会随着进程结束丢失。官方 getting started 文档也提醒,示例里的 in-memory client 主要用于简单入门,如果需要持久化,应使用 persistent client 或 client-server 模式。
方式二:持久化客户端 (PersistentClient):数据保存在磁盘,程序退出后不丢失,是最推荐的本地开发和生产模式。
import chromadb
client = chromadb.PersistentClient(path="./chroma_data")
collection = client.get_or_create_collection(name="rag_demo")这样数据会落到本地目录,适合个人 Demo、小工具、离线实验。
方式三:HTTP API Server (生产部署):启动 server,让多个应用连接同一个 Chroma 服务。
chroma run --path ./chroma_db然后在 Python 里用 HTTP Client 连接:
import chromadb
client = chromadb.HttpClient(host="localhost", port=8000)
collection = client.get_or_create_collection(name="rag_demo")如果你更习惯 Docker,也可以参考 Spring AI 文档中的本地启动方式:
docker run -it --rm --name chroma -p 8000:8000 ghcr.io/chroma-core/chroma:1.0.0实际开发时可以按阶段选择:
学 API:
chromadb.Client()本地 Demo:
PersistentClientJava / 多服务集成:
chroma run或 Docker server生产托管:Chroma Cloud 或其他托管方案
四、Chroma 常用语法:Collection、Add、Query、Filter、Update
Chroma 的 API 很适合初学者理解向量数据库的基本动作。
1. 创建 Collection
import chromadb
client = chromadb.PersistentClient(path="./chroma_data")
collection = client.get_or_create_collection(name="knowledge_base")get_or_create_collection 比 create_collection 更适合脚本反复执行,不会因为 collection 已存在就失败。
2. 添加文档
collection.add(
ids=["refund-001", "refund-002"],
documents=[
"订单进入结算流程后,不支持原路退款。",
"人工退款需要运营提交申请,财务审批后处理。"
],
metadatas=[
{"doc_type": "policy", "product": "payment", "version": "2026"},
{"doc_type": "sop", "product": "payment", "version": "2026"}
]
)只传 documents 时,Chroma 会根据 collection 的 embedding function 处理向量(注:默认 embedding 会去联网下载/调用模型,可能超时)。如果你已经有 embedding,可以直接传:
collection.add(
ids=["refund-003"],
embeddings=[[0.12, 0.08, 0.33]],
documents=["退款失败时,请先检查订单状态和支付渠道。"],
metadatas=[{"doc_type": "faq", "product": "payment"}]
)实际项目里,更常见的是应用层统一调用 Embedding 模型,然后把 embedding、document、metadata 一起写入。这样更容易控制模型版本和向量维度。
Chroma 默认 embedding function / all-MiniLM-L6-v2
3. 查询相似内容
results = collection.query(
query_texts=["订单结算后还能退款吗?"],
n_results=3
)
print(results["documents"])
print(results["metadatas"])
print(results["distances"])返回结果通常包括:
idsdocumentsmetadatasdistancesembeddings,默认通常不返回
n_results 控制返回多少条相似结果。如果不传,Chroma 默认返回 10 条结果。
4. metadata 过滤
Chroma 的 where 参数用于 metadata filter。例如只查支付产品线:
results = collection.query(
query_texts=["订单结算后还能退款吗?"],
n_results=3,
where={"product": "payment"}
)查版本为 2026 且产品为 payment:
results = collection.query(
query_texts=["退款失败怎么办?"],
n_results=5,
where={
"$and": [
{"product": {"$eq": "payment"}},
{"version": {"$eq": "2026"}}
]
}
)查某些文档类型:
results = collection.get(
where={
"doc_type": {
"$in": ["policy", "faq"]
}
}
)Chroma 支持 $eq、比较、$and、$or、$in、$nin 等过滤方式,也支持数组 metadata 的包含判断。对 RAG 来说,metadata filter 是权限、版本和业务范围控制的基础。
5. 更新和覆盖
如果脚本可能重复执行,通常用 upsert 更省心:
collection.upsert(
ids=["refund-001"],
documents=["订单进入结算流程后,不支持原路退款,需要走人工退款流程。"],
metadatas=[{"doc_type": "policy", "product": "payment", "version": "2026"}]
)工程里建议把 add 和 upsert 的使用边界分清楚:
首次导入:可以用
add增量同步:更适合
upsert删除过期文档:按
doc_id、version、status做批量治理
五、Chroma 适合初学者,但生产落地要注意这些边界
Chroma 很适合入门,但不是说任何规模、任何场景都应该默认选它。
适合 Chroma 的场景:
RAG 学习和课程演示。
本地知识库 Demo。
小团队内部文档问答。
Agent 记忆原型。
轻量语义搜索。
需要快速验证 Embedding 和 chunk 策略的项目。
需要谨慎评估的场景:
亿级向量检索。
高并发线上服务。
强多租户隔离。
复杂权限模型。
强 SLA 和跨地域容灾。
大规模混合检索和复杂排序。
这不是 Chroma 的缺点,而是所有向量数据库选型都要面对的现实:原型阶段看 API 是否顺手,生产阶段看稳定性、扩展性、可观测性、运维能力和成本。
如果把 Chroma 用在企业 RAG 项目里,建议从第一天就做好这些设计:
每个 chunk 都有稳定 ID。
metadata 至少包含
doc_id、title、version、source、permission、status。Embedding 模型名称和版本要记录。
不同 embedding 维度不要混在同一个 collection。
文档删除和版本更新要有同步策略。
对召回结果做日志记录,方便 bad case 归因。
不要把权限控制交给 Prompt。
Chroma 能帮你把向量检索跑起来,但 RAG 系统能不能答准,还取决于文档治理、切块、检索策略、Rerank 和评估闭环。
六、Java 集成:用 Spring AI 连接 Chroma 做 RAG 检索
Java 生态里可以通过 Spring AI 集成 Chroma。这里选择 Spring AI,是因为它的 VectorStore 抽象比较适合 Spring Boot 项目:上层业务不需要直接关心 Chroma 的底层 REST API,只需要注入 VectorStore,然后执行 add 和 similaritySearch。
1. 添加依赖
Spring AI 官方文档中,Chroma Vector Store 的 starter 是:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-chroma</artifactId>
</dependency>如果你还需要 OpenAI Embedding,可以再引入对应模型 starter。实际项目里也可以替换成其他 EmbeddingModel,只要最终提供 Spring AI 的 EmbeddingModel Bean。
2. 配置 Chroma 连接
本地 Chroma 默认可以这样配置:
spring.ai.vectorstore.chroma.client.host=http://localhost
spring.ai.vectorstore.chroma.client.port=8000
spring.ai.vectorstore.chroma.collection-name=knowledge_base
spring.ai.vectorstore.chroma.initialize-schema=true
spring.ai.openai.api.key=${OPENAI_API_KEY}如果使用 Chroma Cloud,还需要配置 API key、tenant name 和 database name。Spring AI 文档中也说明,Chroma Cloud 的 host 通常是 api.trychroma.com,端口为 443,并且需要 key-token、tenant、database 等信息。
3. 注入 VectorStore 写入文档
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
@Service
public class KnowledgeIngestService {
private final VectorStore vectorStore;
public KnowledgeIngestService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public void ingest() {
List<Document> documents = List.of(
new Document(
"订单进入结算流程后,不支持原路退款,需要走人工退款流程。",
Map.of(
"doc_type", "policy",
"product", "payment",
"version", "2026"
)
),
new Document(
"人工退款需要运营提交申请,财务审批通过后处理。",
Map.of(
"doc_type", "sop",
"product", "payment",
"version", "2026"
)
)
);
vectorStore.add(documents);
}
}这里的 vectorStore.add(documents) 会通过配置好的 EmbeddingModel 计算 embedding,并写入 Chroma。
4. 相似度检索
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class KnowledgeSearchService {
private final VectorStore vectorStore;
public KnowledgeSearchService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public List<Document> search(String question) {
return vectorStore.similaritySearch(
SearchRequest.builder()
.query(question)
.topK(5)
.similarityThreshold(0.65)
.build()
);
}
}5. metadata 过滤
企业知识库里,检索时通常要加业务过滤条件。Spring AI 支持 portable metadata filter,并会转换成 Chroma 的 where 表达式。比如只查 payment 产品线、指定文档类型:
public List<Document> searchPaymentDocs(String question) {
return vectorStore.similaritySearch(
SearchRequest.builder()
.query(question)
.topK(5)
.filterExpression("product == 'payment' && doc_type in ['policy', 'sop']")
.build()
);
}这样写的好处是业务代码不直接绑定 Chroma 的 JSON filter 格式,后续如果切换向量数据库,迁移成本会低一些。
6. 一个最小 RAG Controller
import org.springframework.ai.document.Document;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class RagController {
private final KnowledgeSearchService searchService;
public RagController(KnowledgeSearchService searchService) {
this.searchService = searchService;
}
@GetMapping("/rag/search")
public List<String> search(@RequestParam String q) {
return searchService.search(q).stream()
.map(Document::getText)
.toList();
}
}这个例子还没有接大模型,只是把 Chroma 检索结果返回出来。实际 RAG 应用会继续做:
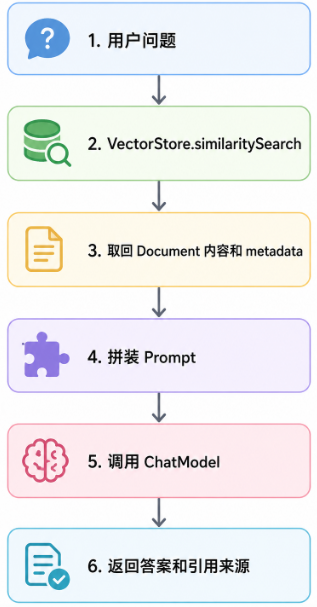
建议初学者先把检索结果调准,再接大模型。否则模型生成的语言会掩盖召回问题,让你误以为系统已经可用。
七、Chroma 实战建议:别只跑通 API,要关注召回质量
Chroma 的 API 很容易跑通,但 RAG 项目真正难的是“找得准”。以下是总结的几点经验:
第一,先做高质量切块。
不要直接把整篇 PDF 或整页 HTML 扔进 Chroma。先去掉页眉、页脚、导航、广告、重复声明,再按标题、段落、列表、表格切成 chunk。
第二,metadata 要从一开始就设计。
至少包括:
doc_id
chunk_id
title
source
version
status
permission
created_at后期再补 metadata 会很痛苦,因为你需要重新同步和重建索引。
第三,记录每次检索日志。
至少记录:
query
topK
where filter
returned ids
distances
metadatas
最终是否被用户采纳RAG 调优不是玄学,bad case 要能追到具体 chunk。
第四,不要迷信向量检索。
Chroma 支持相似度检索,但错误码、字段名、订单号、配置项、接口名这类问题,关键词检索往往更可靠。实际生产里可以考虑 Chroma + 搜索引擎,或者在应用层做 Hybrid Search。
第五,Rerank 仍然有价值。
Chroma 返回的是初始召回结果,不代表最终最适合进入 Prompt。对于复杂问题,可以先召回 top20 或 top50,再用 rerank 模型选 top5。
第六,定期清理旧版本。
企业知识库里最怕新旧制度同时被召回。建议用 version、status、effective_at 控制文档生命周期,不要让过期 chunk 长期混在主 collection 里。
结语:Chroma 是理解 RAG 的好入口,但不是 RAG 的全部
Chroma 的价值,在于它把向量数据库这件事做得足够轻。
你可以很快完成:
安装 Chroma
创建 collection
写入 documents
自动或手动生成 embedding
执行 query
使用 metadata 过滤
接入 Java / Spring AI
对初学者来说,这比一开始研究复杂集群和索引参数更重要。先把 RAG 链路跑通,理解 chunk、embedding、metadata、query、distance、filter、topK 这些基础概念,后面再谈扩容和生产治理会顺很多。
但也要清楚:Chroma 只是 RAG 系统的一部分。一个真正稳定的知识库问答系统,还需要文档清洗、切块策略、Embedding 版本治理、权限控制、Hybrid Search、Rerank、Prompt 约束、引用追踪、评估集和线上反馈。
如果你是第一次做 RAG,我的建议是:先用 Chroma 跑通,再用 bad case 逼出真正的工程需求。当你的问题从“怎么把文档存进去”变成“为什么这个问题召回错了”,你就已经开始真正理解向量数据库了。
评论区