

摘要:Embedding 是 RAG、向量数据库、语义检索和推荐系统里的基础能力。上一篇《RAG 向量数据库入门:从 Embedding 到检索增强生成》已经讲过 RAG 为什么需要 Embedding,本文作为系列专项篇,不再重复 RAG 背景,而是深入解释 Embedding 本身:Token Embedding 为什么本质是查表、Sentence / Document Embedding 如何由模型生成、语义相似度如何计算、常见开源框架和模型如何选择,以及在 RAG 项目中如何评估和治理 Embedding 效果。
写在前面:只讲 Embedding 本身
在上一篇文章《RAG 向量数据库入门与实战:从 Embedding 到检索增强生成》中,我们讲了 RAG 为什么需要 Embedding、向量数据库在 RAG 中做什么、以及“离线建库”和“在线问答”两条链路。
因此,本文不再重复解释 RAG 的整体价值。而是要追问一个更底层的问题:Embedding 到底是怎么把文本变成向量的?
如果用一句话回答,可以总结为:Embedding 是把离散符号映射到连续向量空间,让模型和检索系统可以计算语义距离。
比如一句话:
订单进入结算流程后,不支持原路退款。
经过 Embedding 模型后,会变成一组数字:
[0.012, -0.083, 0.145, ...]这组数字不是给人看的,而是给机器计算的。在 RAG 里,用户问题和文档 chunk 都会被转换成向量。向量距离越近,系统越倾向认为它们语义相关。
本文会从两个层次展开:
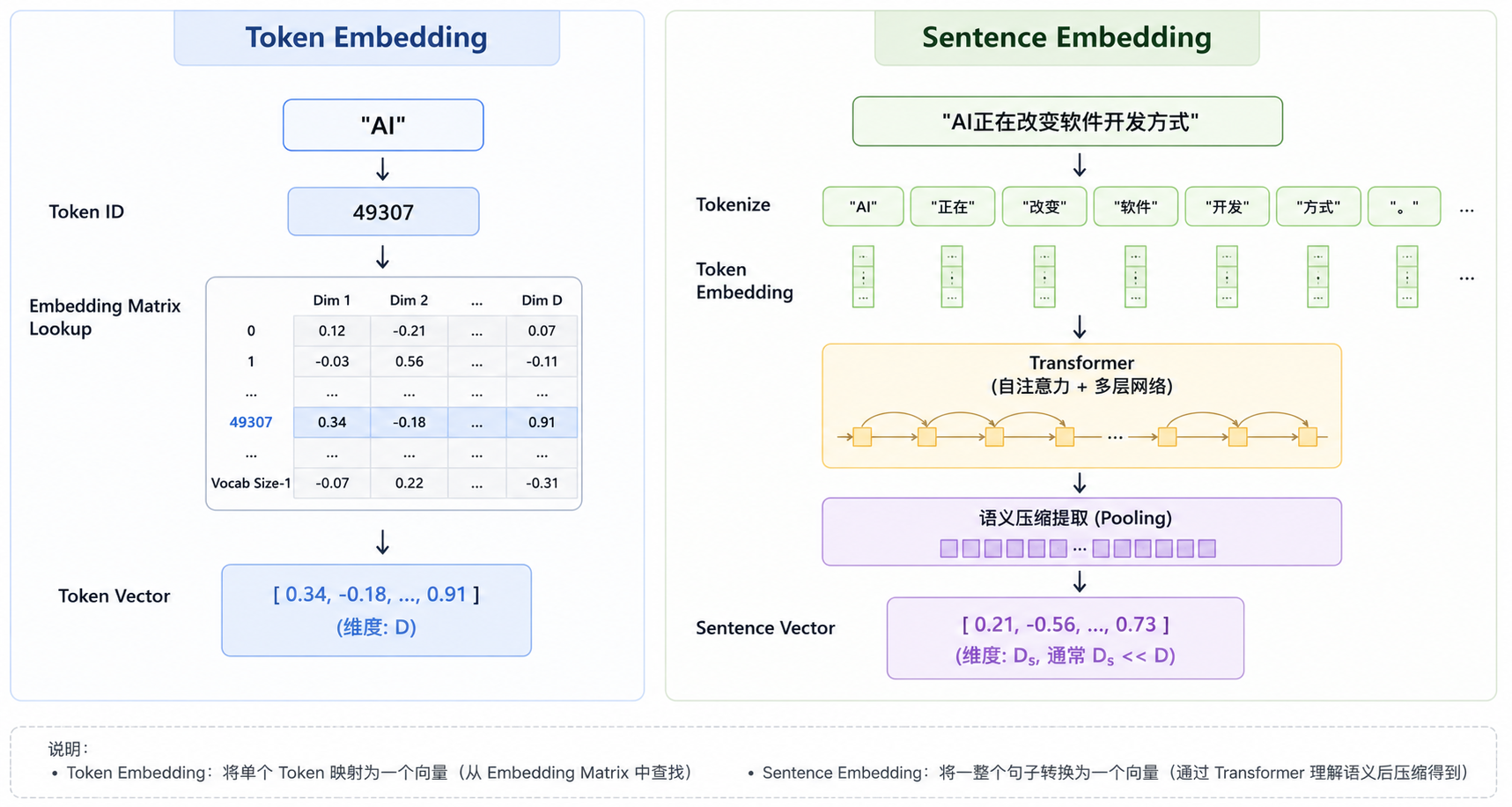
模型内部的 Token Embedding:本质是通过 token ID 查一张可训练矩阵。
RAG 检索里的 Sentence / Document Embedding:通常是文本经过 Transformer 编码和 pooling 后得到的整体向量。
这两个概念经常被混着说,但理解它们的区别很重要。
一、先明确边界:Embedding 不是 RAG 的全部
Embedding 在 RAG 里通常负责“把文本变成可检索的向量”。但 RAG 是否答得准,不只取决于 Embedding。
上一篇 RAG 文章里已经讲过,一条完整链路还包括:
文档解析。
文本切块。
向量数据库。
metadata 过滤。
Hybrid Search。
Rerank。
Prompt 组装。
引用来源。
评估集。
所以这篇文章不会再大段解释“为什么需要 RAG”或者“为什么关键词搜索不够”。而是要把 Embedding 讲深一点:它如何产生、如何选择模型、如何评估,以及为什么它只能解决“召回候选”的一部分问题。
二、Embedding 到底是什么:一组有语义的数字
Embedding 的输出是向量。向量可以理解成一个数字数组:
[0.012, -0.083, 0.145, 0.031, ...]这个数组可能有 384 维、768 维、1024 维、1536 维,甚至更多。维度多少取决于模型。初学者可以先把它想象成一个坐标。在二维地图里,一个点可以用:(x, y)表示位置。
在 Embedding 空间里,一段文本可以用几百到几千个数字表示位置。语义相近的文本,位置更近;语义差异大的文本,位置更远。比如:
“请假需要谁审批?”
“员工休假审批流程是什么?”
这两句话应该距离较近。而:“Redis AOF 持久化怎么配置?”和请假审批的距离应该更远。
这里有一个初学者很容易混淆的地方:大家说 Embedding 时,可能指两件不同层次的东西。
第一种:Token Embedding。
模型内部使用的词向量。它更接近“查表”。
第二种:Sentence / Document Embedding。
RAG、向量数据库、语义搜索中使用的文本向量。它通常指一句话、一段文本、一个 chunk 经过模型编码后得到的整体向量。
这两者相关,但不是一回事。
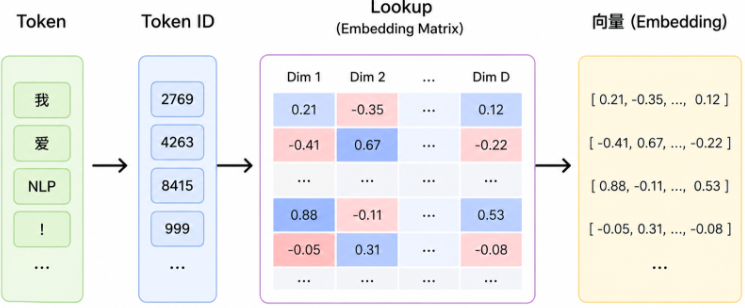
2.1 Token Embedding:本质是一张可训练参数表
在 Transformer 模型内部,可以把 Embedding 看成一张巨大的参数表。
假设:
词表大小 Vocabulary = 50000
Embedding 维度 = 4
那么模型里会有一张矩阵:
Embedding Matrix = 50000 x 4
每一行对应一个 token ID,每一列是这个 token 的一个向量维度。
假设我们有这样一个矩阵:
ID Vector
0 [0.11, 0.23, -0.45, 0.67]
1 [-0.12, 0.89, 0.34, -0.22]
...
1024 [0.42, -0.15, 0.88, 0.36]
3521 [0.71, 0.53, -0.22, 0.14]
19876 [-0.31, 0.67, 0.51, -0.48]如果输入一句话:
我喜欢AI
先经过 tokenizer:
["我", "喜欢", "AI"]
再转换成 token ID:
[1024, 3521, 19876]
然后就去 Embedding Matrix 里取对应行:
1024 -> [0.42, -0.15, 0.88, 0.36]
3521 -> [0.71, 0.53, -0.22, 0.14]
19876 -> [-0.31, 0.67, 0.51, -0.48]最终得到:
[
[0.42, -0.15, 0.88, 0.36],
[0.71, 0.53, -0.22, 0.14],
[-0.31, 0.67, 0.51, -0.48]
]所以从 Token Embedding 这一层看,它确实不是通过某个复杂公式实时算出来的,而是:
公式可以写成:
Embedding(token_id) = Embedding_Matrix[token_id]
GPT-4,业内推测,词表大小约200万,维度8k~16k
为什么这张表会有语义?
这里很多人会误解。虽然计算过程只是查表,但这张表并不是人工写进去的。训练开始时:
AI -> [-0.08, 0.13, 0.04, -0.11]
这些数字几乎是随机的,没有任何语义。随后模型会不断执行:
训练数据足够多、训练目标足够有效时,经常出现在相似上下文里的 token,向量会逐渐靠近。例如:
北京、上海、广州、深圳
可能会在空间里形成一团。
香蕉、橘子、苹果
也可能形成另一团。
而“苹果”这个词如果出现在 iPhone、MacBook、公司财报这些上下文里,它在上下文模型中还会通过 Transformer 后续层被赋予不同语境下的表达。
这也是为什么现代语言模型不能只看第一层 token embedding。真正的上下文理解,是 token embedding 进入 Transformer 后,由多层 self-attention 和前馈网络共同完成的。
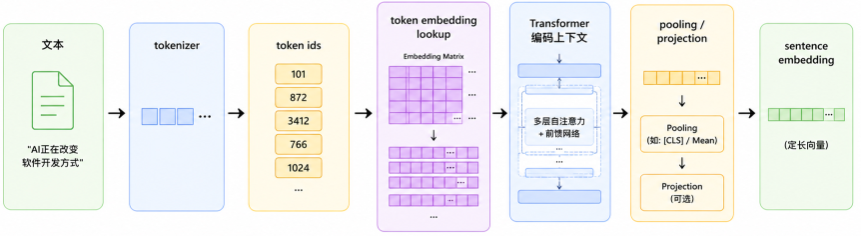
2.2 RAG 里的 Embedding:通常不是简单查表结果
RAG 和向量数据库里说的 Embedding,通常不是某个 token 的查表向量,而是一段文本的整体向量。
例如:
订单进入结算流程后,不支持原路退款。
这个 chunk 可能有十几个 token。模型会先做 token embedding lookup,再经过 Transformer 编码,最后通过 pooling、特殊 token 输出、归一化等方式,把整段文本变成一个固定维度的向量。
简化流程是:
要准确地区分:
Token Embedding 是模型内部给每个 Token 的初始表示;而 RAG 中使用的 Embedding,是整段文本经过 Transformer 编码后得到的语义表示。
前者解决“如何把文字变成数字”。
后者解决“如何让数字真正表达语义”。
而向量检索、Milvus、pgvector、Chroma、LangChain、Spring AI 等 RAG 体系所使用的,几乎都是后者。
2.3 为什么要从离散 ID 变成连续向量
Token ID 本身只是编号。比如:
我 = 1024
喜欢 = 3521
AI = 19876
这些数字没有语义上的大小关系。不能因为:
19876 > 1024
就说:
AI > 我
这没有任何意义。Token ID 是离散符号,只适合做索引,不适合直接做语义计算。Embedding 把离散 ID 映射到连续向量空间:
AI -> [-0.31, 0.67, 0.51, -0.48]
进入连续空间后,模型和检索系统就可以计算:
距离。
相似度。
方向。
聚类关系。
比如余弦相似度越接近 1,通常表示两个向量方向越接近,语义也可能越相似。
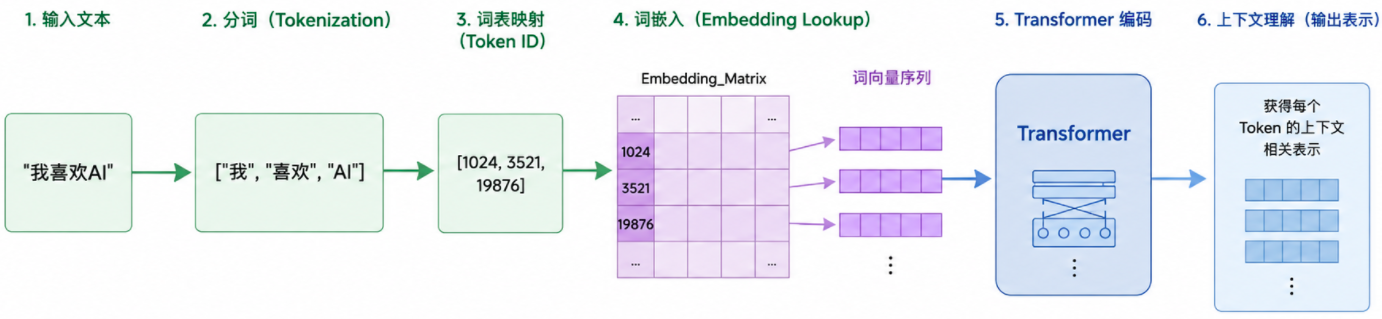
2.4 为什么 Transformer 必须先做 Embedding
Transformer 不能直接处理字符串。它内部做的是大量矩阵运算:
Q = XWq
K = XWk
V = XWv
这里的 X 必须是数字矩阵。原始文本:
"AI"
"退款"
"订单"
不能直接参与矩阵乘法。所以必须先做:
文字 -> token -> token id -> embedding lookup -> 数字矩阵 X -> Transformer
可以把整体流程记成:
2.5 相似度怎么计算
Embedding 生成之后,需要用相似度函数判断两个向量是否接近。常见方法有三种:
Cosine Similarity
余弦相似度看两个向量方向是否接近。文本语义检索中非常常见。
Dot Product
点积会计算两个向量的乘积和。有些模型训练时就针对点积相似度做了优化。
Euclidean Distance
欧氏距离就是空间里的直线距离,距离越小越接近。
不要随便混用相似度算法。最好看模型文档推荐什么距离函数。模型训练目标和检索时使用的距离函数不匹配,效果可能会变差。
三、Embedding 是怎么生成的
Embedding 不是普通哈希。
哈希强调唯一性:两个文本只要有一点不同,哈希值就可能完全不同。
Embedding 强调语义相似:两句话字面不同,但意思相近,向量距离应该接近。
生成 Embedding 的典型流程是:文本 -> tokenizer 分词 -> embedding 模型编码 -> pooling / 向量输出 -> 可选归一化 -> 存储或检索
3.1 文本预处理
在 RAG 场景里,原始文档通常不能直接送进 Embedding 模型。你需要先做:
去掉页眉、页脚、广告、导航。
保留标题、章节、表格说明。
把长文档切成 chunk。
给 chunk 加 metadata。
控制 chunk 长度,避免超过模型输入上限。
Embedding 模型再强,也救不了脏数据。如果 PDF 解析错乱、表格列名和值分离、标题丢失,生成出来的向量也会跟着混乱。
3.2 文本切块
Embedding 通常不是对整本书、整份合同、整套文档一次性生成向量,而是对 chunk 生成。比如:
文档 -> 章节 -> 段落 -> chunk -> embedding
切块太小,语义不完整。
切块太大,噪声太多,召回精度下降,也会增加 token 成本。
初学者可以先用一个稳妥策略:
按标题和段落切。
保留列表和表格的完整性。
chunk 控制在几百到一千多 token。
给 chunk 带上标题路径。
不要一开始就只按固定字符数硬切。
3.3 调用模型生成向量
以 Sentence Transformers 为例:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-m3")
texts = [
"订单进入结算流程后,不支持原路退款。",
"人工退款需要运营提交申请,财务审批通过后处理。"
]
embeddings = model.encode(texts, normalize_embeddings=True)
print(embeddings.shape)输出结果就是一个二维数组:
文本数量 x 向量维度
如果有 2 段文本,每段向量是 1024 维,那么输出形状就是:
(2, 1024)
3.4 存入向量数据库
向量一般不会单独存。通常会和原文、ID、metadata 一起存入向量数据库:
{
"id": "refund-policy#chunk-001",
"text": "订单进入结算流程后,不支持原路退款。",
"embedding": [0.012, -0.083, 0.145],
"metadata": {
"doc_id": "refund-policy",
"title": "退款规则",
"version": "2026",
"permission": "support"
}
}用户提问时,再把问题也转换成向量:
用户问题 -> query embedding -> 向量数据库相似度检索 -> 返回最相关 chunk
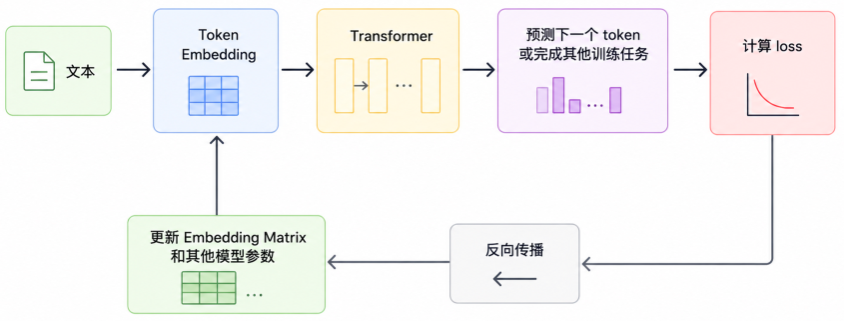
四、Embedding 在 RAG 中怎么用
RAG 完整链路在前文已经讲过,这里只看 Embedding 负责的那一小段。它做两件事。
离线阶段把文档 chunk 转成 document embedding。
在线阶段把用户问题转成 query embedding。
然后向量数据库计算 query embedding 和 document embedding 的相似度,找出候选 chunk。简化后是:
document chunk -> document embedding
user query -> query embedding
query embedding vs document embedding -> 相似度检索这里要注意一个关键点:document embedding 和 query embedding 必须可比较。
通常来说,文档和问题要使用同一个 Embedding 模型,或者使用同一个模型体系里专门训练好的 query encoder / document encoder。
如果文档用模型 A 生成向量,问题用模型 B 生成向量,而且两个模型不是同一向量空间,检索结果就会变得不可控。
4.1 query 和 document 要不要加前缀
有些 Embedding 模型建议加前缀,例如:
query: 订单结算后还能退款吗?
passage: 订单进入结算流程后,不支持原路退款。
这样模型能区分“用户问题”和“候选资料”的角色。但不是所有模型都需要前缀。是否加前缀,要看模型说明。最怕的是同一个系统里一部分数据加了前缀,一部分没加;或者入库时没加,查询时乱加。这样会让召回效果不稳定。
4.2 Embedding 只负责召回,不负责最终判断
Embedding 在 RAG 里通常负责“宽召回”。它把可能相关的资料找出来,但不保证排第一的就是最能回答问题的资料。所以很多生产 RAG 会加一层 Rerank:
向量召回 top50 -> Rerank -> 选择 top5 -> 放进 Prompt
Embedding 负责把候选证据找出来,Rerank 负责把更适合回答问题的证据排到前面。
五、常见 Embedding 框架和模型推荐
Embedding 可以用商业 API,也可以用开源模型。初学阶段,建议先用成熟工具跑通流程,再逐步比较不同模型效果。
1. OpenAI Embeddings
OpenAI 提供专门的 Embeddings API,可以把输入文本转换成向量,常用于搜索、聚类、推荐、异常检测、分类等场景。
优点:
API 简单。
稳定性好。
不需要自己部署模型。
适合快速构建 RAG 或语义搜索原型。
缺点:
需要外部 API。
有调用成本。
数据出境和合规要评估。
适合:
快速产品验证。
不想维护模型服务。
对稳定性和开发效率要求高的团队。
2. Sentence Transformers
Sentence Transformers 是非常常用的开源文本向量框架,适合生成句向量、做语义相似度、语义搜索和聚类。一个最小示例:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
sentences = [
"How do I reset my password?",
"What should I do if I forgot my password?"
]
embeddings = model.encode(sentences)优点:
上手简单。
模型丰富。
本地可运行。
适合教学、Demo 和中小规模实验。
适合:
初学者。
本地 RAG 实验。
英文语义搜索。
快速比较不同模型。
3. FlagEmbedding / BGE 系列
FlagEmbedding 是 BAAI BGE 系列模型常用工具,覆盖 embedding、reranker 等检索增强模型。
在中文和中英混合 RAG 场景里,BGE 系列很常见,尤其是 BGE-M3 这类多语言、多功能检索模型,经常被用作开源 RAG 的候选方案。
优点:
对中文和多语言场景友好。
检索和 rerank 生态比较完整。
适合 RAG 项目做本地化和私有化部署。
适合:
中文知识库。
中英混合文档。
企业私有化部署。
希望 embedding 和 reranker 一起评估的团队。
4. Hugging Face Transformers
Transformers 更底层,也更灵活。
如果你需要自定义 pooling、微调模型、导出 ONNX、做推理优化,或者想把 embedding 模型放进自己的模型服务里,Transformers 会比简单封装更可控。适合:
有模型工程经验的团队。
需要微调或自定义推理流程。
需要统一管理多种开源模型。
5. Hugging Face Text Embeddings Inference
当 embedding 请求量变大后,单机脚本 model.encode() 不一定够用。
Hugging Face Text Embeddings Inference 是一个面向 embedding 和 reranking 模型的高性能服务化方案,适合把模型部署成可被多个应用调用的服务。适合:
大批量文档入库。
多应用共享 embedding 服务。
GPU 推理。
需要监控、批处理和线上服务能力。
6. Ollama Embeddings
Ollama 常用于本地运行模型,也提供 embeddings API。
它适合在开发机或内网环境快速启动一个本地 embedding 服务。适合:
本地开发。
数据不方便发到外部服务。
轻量 Demo。
内网验证。
怎么推荐
如果只是学习:
Sentence Transformers + all-MiniLM-L6-v2
简单、轻量、资料多。
如果做中文 RAG:
BAAI/bge-m3
BGE 中文/多语言系列
更值得优先测试。
如果追求省心和稳定:
OpenAI Embeddings API
适合快速上线,但要考虑成本和合规。
如果要内网私有化:
FlagEmbedding / Transformers / TEI / Ollama
根据并发、GPU、运维能力选择。
真正做生产项目时,不要只看别人推荐。最可靠的方法是拿自己的数据做评估。
六、怎么选择 Embedding 模型
选 Embedding 模型时,不要只看排行榜。排行榜能提供参考,但真实业务数据往往更复杂。可以按下面几个维度判断。
1. 语言
中文文档、英文文档、中英混合文档,对模型要求不同。
如果你的知识库主要是中文,不要只用英文效果好的模型;如果文档里有大量英文 API、代码类名、错误码,也要单独测试。
2. 领域
客服、法律、金融、医疗、代码、运维、教育,每个领域的表达都不一样。
通用模型可能知道“退款”和“退钱”相近,但未必理解你公司内部的产品名、流程名、配置项和缩写。
3. 输入长度
有些 embedding 模型适合短句,有些支持更长上下文。
如果你的 chunk 很长,要关注模型最大输入长度。超长文本被截断后,向量可能丢失关键信息。
4. 向量维度
向量维度越高,不一定效果越好,但通常会带来更多存储和计算成本。
比如同样是一百万个 chunk:
384 维向量更省存储。
1024 维向量可能表达能力更强,但成本更高。
维度选择要结合效果和成本一起看。
5. 延迟和吞吐
Embedding 不只在线查询时用,也会在文档入库时大量调用。
如果每天要处理几十万、几百万个 chunk,就要考虑批处理、GPU、限流、重试和成本。
6. 是否需要 reranker
有些团队希望 embedding 一步到位,但实际检索常常需要两阶段:
Embedding 召回候选
Reranker 精排结果
尤其是知识库规模变大、问题更复杂、候选 chunk 相似度接近时,reranker 的收益会很明显。
七、Embedding 落地时最容易踩的坑
1. 不同模型的向量混在一起
这是很常见的坑。
不同 embedding 模型生成的向量不在同一个空间里。把模型 A 和模型 B 的向量混在同一个 collection 里,距离计算就会变得没有意义。正确做法:
模型升级时新建 collection 或 index version。
metadata 里记录 embedding 模型和版本。
回滚策略提前设计。
2. 文档和问题用的模型不一致
入库时用一个模型,查询时换另一个模型,会导致召回不稳定。除非你使用的是同一模型体系里明确支持的 query encoder / document encoder,否则不要混用。
3. chunk 质量太差
Embedding 不是清洗工具。
如果 chunk 里混了页码、版权声明、导航菜单、错位表格,模型只能把这些噪声也编码进去。好的向量检索,先从好的文档解析和切块开始。
4. 只用向量检索
向量检索适合语义相似,不擅长所有问题。这些场景关键词搜索更强:
错误码。
订单号。
字段名。
API 名称。
配置项。
法条编号。
生产 RAG 通常要做 Hybrid Search。
5. topK 越大越好
topK 变大,召回率可能提高,但噪声也会增加。
如果把太多不相关 chunk 放进 Prompt,大模型反而更容易答偏。更稳的做法是:适当扩大召回 topK -> rerank -> 去重和压缩 -> 只把高质量证据放进 Prompt
6. 没有记录日志
Embedding 检索问题很难凭感觉排查。至少要记录:
query
embedding model
topK
metadata filter
召回 chunk id
相似度分数
rerank 分数
最终进入 Prompt 的 chunk
用户反馈
没有日志,就没有可复盘的优化。
结语:Embedding 是语义检索的起点,不是终点
Embedding 很重要,但不要把它神化。它解决的是“把语义变成可计算的向量”。
在 RAG 系统里,它通常负责把可能相关的资料召回出来。至于一个完整 RAG 系统还需要哪些组件,前面的 RAG 总篇已经展开过:文档解析、切块、向量数据库、metadata、Hybrid Search、Rerank、Prompt、引用和评估,都在那条链路里。
这篇文章只补上其中最容易被一句话带过、但又最影响召回质量的一层:Embedding。
对于初学者来说,学习顺序可以是:
先读 RAG 总篇,理解完整链路
再读 Embedding 专项篇,理解向量是怎么来的
最后用 bad case 反推模型、切块和检索策略
然后再问:
为什么这个问题没召回?
为什么正确 chunk 排在后面?
为什么同义问题效果不同?
为什么换了模型反而变差?
能回答这些问题,才算真正理解 Embedding。
一句话总结:
Embedding 不是让机器读懂文本的终点,而是让机器开始计算语义的入口。
评论区