摘要:本文全面解析RAG(检索增强生成)技术,从核心原理到Graph RAG、Agentic RAG等前沿形态,结合Spring AI Alibaba实战代码,详解企业落地RAG的关键挑战与解决方案。适合需要构建知识库问答、智能客服、数据分析等AI应用的开发者。
前言:为什么RAG成为大模型应用落地的标配
最近公司上线或在做了几个企业AI项目,无一例外都用了RAG。不是因为RAG有多神奇,而是因为它是目前解决大模型"不知道企业私有数据"这个问题最务实的方法。
让大模型直接回答"公司上季度的毛利率是多少",它会说不知道。即使你把财报贴给它,它也记不住,下次还得再贴。RAG的本质就是:每次回答问题时,先去知识库里找相关资料,然后带着资料一起问大模型。这样大模型每次都能"看到"最新的数据。
听起来简单,但真正落地时坑不少。文档切分怎么切、向量检索召回率不够、知识库更新不及时、复杂问题检索不到关键信息……这些问题不解决,RAG就是花架子。
这篇文章会从RAG的基础原理讲起,重点介绍Graph RAG、Agentic RAG这些新形态,最后用Spring AI Alibaba给出完整的落地代码。希望能帮你在实际项目中少踩坑。
一、RAG核心原理
1.1 什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大模型结合外部知识库生成答案的技术架构。
核心流程:用户提问 → 向量化 → 检索知识库 → 获取相关文档 → 拼接上下文 → 大模型生成答案
用一个比喻来理解:大模型像一个博览群书的学者,但你公司的内部资料他没看过。RAG就像是每次考试前,先从图书馆找出相关的几本书,摆在桌上让他参考。这样他就能基于这些资料回答问题。
1.2 为什么需要RAG
大模型有几个先天局限:
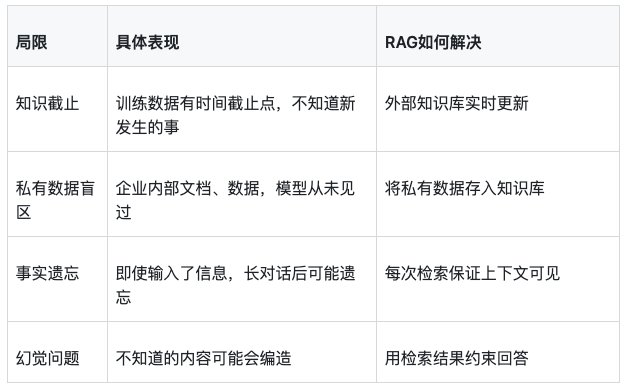
简单说,RAG让大模型从"靠记忆回答"变成"查资料回答"。后者显然更可靠。
1.3 RAG与微调的区别
很多开发者会问:为什么不直接微调模型,让它记住企业知识?两者对比:
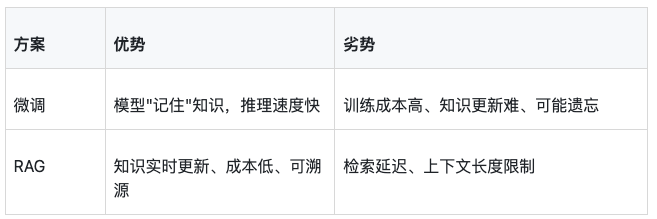
实际项目中,我的经验是:
知识稳定、需要深度内化的 → 微调更合适(如医疗诊断规则)
知识频繁更新、需要溯源的 → RAG更合适(如政策法规问答)
两者可以结合:微调改能力,RAG补知识
绝大多数企业应用,RAG就够了。微调更多是锦上添花。
二、RAG的多种形态
RAG不是一种固定架构,而是不断演进的范式。从最简单的Naive RAG,到复杂的Graph RAG、Agentic RAG,不同形态适应不同场景。
2.1 Naive RAG(基础RAG)
最基础的RAG形式,流程简单直接:
流程:
Query → Embedding → Vector Search → Top-K Documents → Concatenate → Generate
特点:
单次检索,直接取最相似的K个文档片段
不做查询优化,不做结果重排
实现简单,适合入门和简单问答场景
局限性:
检索精度有限,可能召回无关内容
复杂问题难以精准匹配
上下文可能冗余或缺失关键信息
适用场景:
简单FAQ、文档查询、单主题问答
2.2 Advanced RAG(高级RAG)
在基础RAG上增加检索前后的优化环节:
检索前优化(Pre-Retrieval):
// 查询改写
Query Rewrite: "怎么退货" → "退货流程步骤是什么"
// 查询扩展
Query Expansion: "退货" → ["退货流程", "退货条件", "退货时效"]
// HyDE(假设文档嵌入)
让模型先生成假设答案,再用假设答案去检索检索后优化(Post-Retrieval):
// 重排序(Re-ranking)
用Cross-Encoder对召回结果精排,提升相关性
// 上下文压缩
去除冗余内容,压缩到核心信息,节省Token
// 元数据过滤
按时间、来源、类别等过滤,提升精准度检索优化(Indexing):
混合检索:向量检索 + 关键词检索(BM25)
分层索引:粗粒度索引快速定位,细粒度索引精确召回
父子文档:召回子片段,返回父文档完整内容
适用场景:
领域问答、客服系统、知识库检索
2.3 Modular RAG(模块化RAG)
最灵活的架构,可以自由组合、替换、编排各模块:
核心模块:
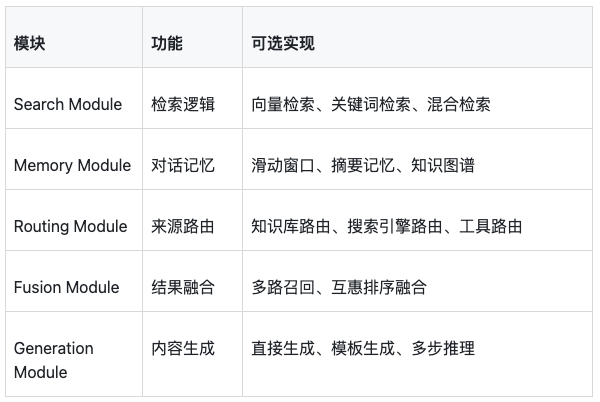
编排能力:
// 可以跳过某些模块
Query → Routing → (跳过Memory) → Fusion → Generate
// 可以循环某些模块
Query → Rewrite → Search → Judge(不够) → Rewrite → Search → Generate
// 可以并行某些模块
Query → [VectorSearch, KeywordSearch] → Fusion → Generate适用场景:
复杂问答系统、多知识源融合、需要灵活定制流程
2.4 Graph RAG(图结构RAG)
这是微软研究院2024年提出的新范式,核心思想是:用知识图谱组织文档,检索时沿着图结构追溯相关信息。
为什么需要Graph RAG:
传统向量检索的问题:
文档片段孤立,不知道片段之间的关系
复杂问题需要跨多个片段综合理解
向量相似度无法表达实体间的逻辑关系
比如问"公司今年的研发投入对产品竞争力有什么影响",这个问题涉及多个实体(研发投入、产品、竞争力)和它们之间的关系。纯向量检索很难把相关片段都找出来。
Graph RAG的流程:
Step 1: 文档处理
Documents → Extract Entities/Relations → Build Knowledge Graph
Step 2: 图索引
Knowledge Graph → Community Detection → Community Summaries
Step 3: 查询处理
Query → Identify Relevant Communities → Retrieve Community Summaries
Step 4: 生成答案
Query + Community Summaries → Generate Comprehensive Answer核心创新点:
实体抽取与关系构建。从文档中抽取实体(人、物、概念)和关系,构建知识图谱:
Document: "张三负责产品A的开发,产品A解决了客户B的需求"
Extract:
- Entities: 张三, 产品A, 客户B
- Relations: 张三→负责→产品A, 产品A→解决→客户B需求社区发现与摘要
将图谱划分为多个社区(相关实体聚集),每个社区生成摘要:
Community: [张三, 产品A, 产品B, 开发团队]
Summary: "开发团队由张三等人组成,负责产品A和B的开发工作"基于社区的检索
查询时定位相关社区,获取社区摘要,获得更完整的上下文:
Query: "张三负责什么工作"
Process:
1. 定位实体: 张三
2. 定位社区: 开发团队社区
3. 获取摘要: "开发团队由张三等人组成,负责产品A和B的开发工作"
4. 生成答案: 张三负责产品A和B的开发工作Graph RAG的优势:
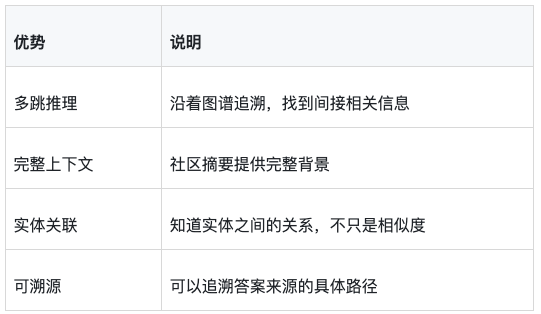
Graph RAG的挑战:
实体抽取准确性依赖模型能力
图谱构建成本高,需要处理大量文档
图维护复杂,文档更新要同步更新图
适用场景受限,不是所有问题都需要图谱
适用场景:
复杂知识问答、多实体关联分析、研究报告生成、需要推理链的问题
2.5 Agentic RAG(智能体RAG)
这是近期最受关注的新形态,核心思想是:让智能体自主决定如何检索、何时检索、用什么策略检索。
传统RAG vs Agentic RAG:
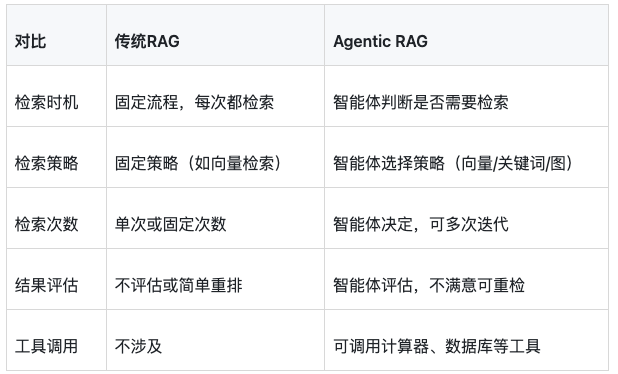
Agentic RAG的流程:
Query → Agent接收 → 判断是否需要检索 → 选择检索策略 → 执行检索 → 评估结果
→ (不满意) → 改写查询 → 重新检索 → ...
→ (满意) → 整合信息 → 生成答案 → (需要补充) → 调用工具 → ...核心能力:
动态查询路由
智能体根据问题类型决定检索源:
Query: "今天的股价是多少"
Agent Decision: 调用实时数据API,不检索知识库
Query: "公司的估值方法是什么"
Agent Decision: 检索知识库文档
Query: "分析公司近三年业绩趋势"
Agent Decision: 检索历史财报 + 调用数据分析工具自适应检索策略
智能体选择最合适的检索方法:
简单问题: 向量检索即可
复杂问题: 混合检索 + 重排序
多实体问题: Graph RAG
实时数据: 调用API而非检索文档迭代检索与评估
智能体可以判断检索结果是否充分:
第一次检索结果: 3个文档片段,信息不完整
Agent判断: 需要更多信息
行动: 改写查询词,重新检索
第二次检索结果: 5个文档片段,覆盖了关键点
Agent判断: 信息充分,可以回答多工具协同
检索只是能力之一,智能体可以调用多种工具:
Agent可调用工具:
1. vector_search - 向量检索知识库
2. keyword_search - 关键词检索
3. graph_query - 知识图谱查询
4. database_query - 数据库查询
5. web_search - 网络搜索
6. calculator - 数学计算
7. api_call - 外部接口调用Agentic RAG的典型实现:
@Service
public class AgenticRAGAssistant {
private final ChatClient chatClient;
private final VectorStore vectorStore;
private final KnowledgeGraphStore graphStore;
private final DatabaseTool dbTool;
private final ApiTool apiTool;
public AgenticRAGAssistant(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("""
你是智能问答助手。
回答问题时请遵循以下原则:
1. 先判断问题类型,决定是否需要检索外部信息
2. 根据问题特点选择最合适的检索或查询方式
3. 如果检索结果不完整,可以改写查询重新检索
4. 如果需要实时数据,调用API而非检索文档
5. 如果需要计算分析,调用计算工具
6. 整合所有信息后生成完整答案
""")
.defaultFunctions(
new VectorSearchTool(vectorStore),
new KeywordSearchTool(),
new GraphQueryTool(graphStore),
dbTool,
apiTool,
new CalculatorTool()
)
.build();
}
public String query(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}Agentic RAG的优势:
灵活性强,适应各种问题类型
检索效率高,不需要每次都检索
答案质量好,智能体持续优化直到满意
能力扩展方便,可以接入各种工具
Agentic RAG的挑战:
智能体决策可能出错,选错检索策略
多次迭代可能导致延迟增加
成本更高,每次决策都要调用模型
实现复杂度明显高于传统RAG
适用场景:复杂问答系统、数据分析智能体、需要多能力协同的场景
三、RAG形态对比与选择
3.1 各形态对比
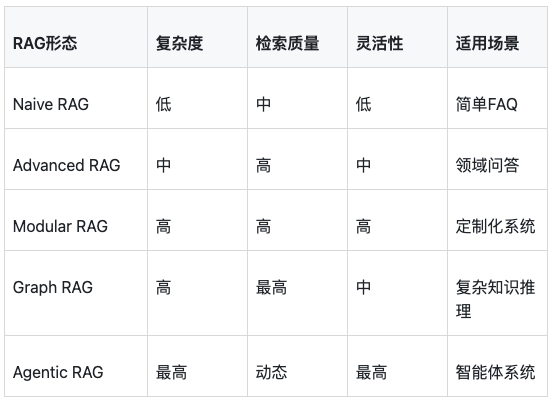
3.2 选择建议
根据实际场景选择合适的RAG形态:
简单FAQ系统 → Naive RAG
文档不多、问题简单、答案明确,基础RAG足够。
客服/知识库问答 → Advanced RAG
需要处理用户各种表述方式,需要召回精准,增加查询改写、重排序等优化。
多知识源融合 → Modular RAG
知识分散在不同系统(文档库、数据库、网页),需要灵活编排检索流程。
复杂知识推理 → Graph RAG
问题涉及多个实体、需要追溯关系链、需要综合多篇文档,用图结构组织知识。
智能分析助手 → Agentic RAG
不只是查文档,还需要调用工具、分析数据、迭代优化,让智能体自主决策。
实际项目中,往往是组合使用:基础用Advanced RAG,特定场景引入Graph RAG,整体用Agentic RAG框架编排。
四、RAG落地实践
4.1 文档处理的关键环节
RAG效果好不好,很大程度上取决于文档处理质量。
文档加载
不同格式需要不同处理方式:
// PDF文档
PDFDocumentReader pdfReader = new PDFDocumentReader();
List<Document> pdfDocs = pdfReader.read(pdfFile);
// Word文档
WordDocumentReader wordReader = new WordDocumentReader();
// 网页文档
WebDocumentReader webReader = new WebDocumentReader();
// 结构化数据(数据库、表格)
StructuredDataReader dbReader = new StructuredDataReader();文档清洗
原始文档有很多噪音需要清理:
public Document cleanDocument(Document rawDoc) {
String content = rawDoc.getContent();
// 去除HTML标签
content = removeHtmlTags(content);
// 去除乱码和特殊字符
content = removeNoise(content);
// 去除重复内容(如页眉页脚)
content = removeDuplicates(content);
// 统一格式(换行、空格)
content = normalizeFormat(content);
return new Document(content, rawDoc.getMetadata());
}文档切分
切分策略决定检索粒度,是最关键的环节:
// 固定长度切分(最简单)
TokenTextSplitter fixedSplitter = new TokenTextSplitter(500, 50);
// 每500Token一个片段,相邻片段重叠50Token
// 语义切分(推荐)
SemanticTextSplitter semanticSplitter = new SemanticTextSplitter();
// 根据语义边界切分,不切断完整段落
// 按标题切分
HeadingTextSplitter headingSplitter = new HeadingTextSplitter();
// 每个章节/段落作为独立片段
// 父子切分
ParentChildSplitter pcSplitter = new ParentChildSplitter();
// 切成小片段用于检索,但返回时带上父文档完整内容我的经验是:固定长度切分效果最差,经常把相关内容切断。语义切分效果好,但依赖切分模型。按标题切分最实用,大部分文档都有章节结构。
元数据标注
为每个片段添加元数据,便于后续过滤和溯源:
Document chunk = new Document(content, Map.of(
"source", "产品手册.pdf",
"page", 15,
"section", "产品规格",
"category", "技术文档",
"updated_at", "2024-10-01",
"version", "v2.1"
));4.2 向量化和存储
选择嵌入模型
嵌入模型质量直接影响检索效果:
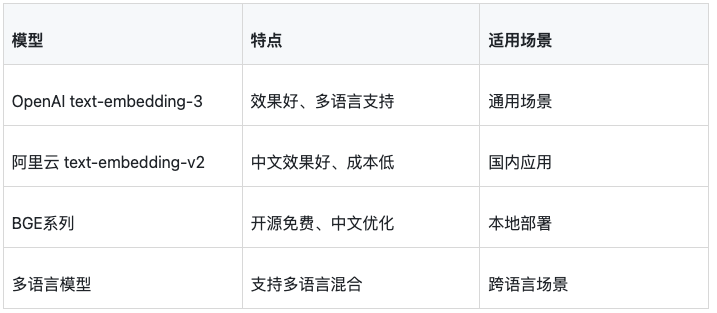
批量向量化
大量文档要分批处理,避免API限流:
public void batchEmbed(List<Document> documents) {
int batchSize = 100;
for (int i = 0; i < documents.size(); i += batchSize) {
List<Document> batch = documents.subList(i, Math.min(i + batchSize, documents.size()));
List<float[]> embeddings = embeddingModel.embedAll(batch);
for (int j = 0; j < batch.size(); j++) {
batch.get(j).setEmbedding(embeddings.get(j));
}
vectorStore.add(batch);
// 防止限流
Thread.sleep(1000);
}
}选择向量存储
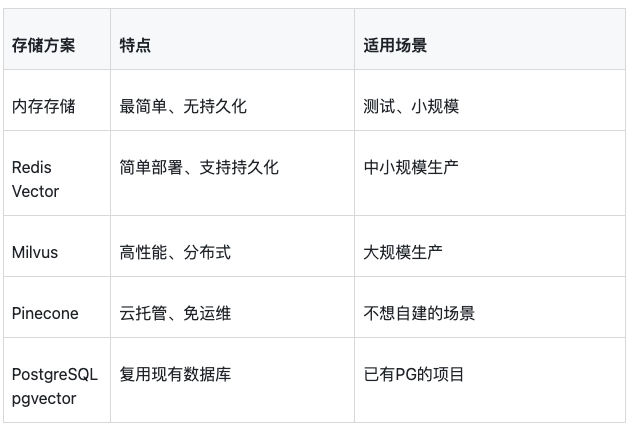
4.3 检索优化策略
混合检索
向量检索擅长语义匹配,关键词检索擅长精确匹配,两者结合效果更好:
public List<Document> hybridSearch(String query) {
// 向量检索
List<Document> vectorResults = vectorStore.search(query, topK=10);
// 关键词检索(BM25)
List<Document> keywordResults = keywordIndex.search(query, topK=10);
// 融合排序(互惠排序融合)
List<Document> fusedResults = reciprocalRankFusion(
vectorResults, keywordResults
);
return fusedResults;
}
private List<Document> reciprocalRankFusion(
List<Document> list1, List<Document> list2
) {
Map<String, Double> scores = new HashMap<>();
for (int i = 0; i < list1.size(); i++) {
String id = list1.get(i).getId();
scores.put(id, scores.getOrDefault(id, 0.0) + 1.0 / (i + 60));
}
for (int i = 0; i < list2.size(); i++) {
String id = list2.get(i).getId();
scores.put(id, scores.getOrDefault(id, 0.0) + 1.0 / (i + 60));
}
return scores.entrySet()
.stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.map(e -> findDocument(e.getKey(), list1, list2))
.limit(topK)
.toList();
}重排序
向量检索是粗召回,用Cross-Encoder精排可以大幅提升相关性:
public List<Document> rerank(String query, List<Document> candidates) {
CrossEncoderReranker reranker = new CrossEncoderReranker();
// 计算每个候选文档与查询的精确相似度
List<Double> scores = reranker.score(query, candidates);
// 按分数排序
return candidates.stream()
.sorted(Comparator.comparingDouble(doc -> -scores.get(candidates.indexOf(doc))))
.limit(finalK)
.toList();
}查询改写
用户表述可能不精确,需要改写成更适合检索的形式:
public String rewriteQuery(String originalQuery) {
String rewritePrompt = """
用户问题:%s
请将问题改写为更适合检索的形式:
1. 补充缺失的关键词
2. 纠正可能的表述错误
3. 添加相关扩展词
直接输出改写后的查询,不要解释。
""".formatted(originalQuery);
return chatClient.prompt()
.user(rewritePrompt)
.call()
.content();
}多路查询
复杂问题拆成多个子查询,提高召回率:
public List<Document> multiQuerySearch(String query) {
// 让模型生成多个查询变体
List<String> queries = generateQueryVariants(query);
List<Document> allResults = new ArrayList<>();
for (String q : queries) {
allResults.addAll(vectorStore.search(q, topK=5));
}
// 去重并重排
return deduplicateAndRerank(query, allResults);
}
private List<String> generateQueryVariants(String query) {
String prompt = """
用户问题:%s
请生成3个不同表述方式的查询,用于检索相关信息:
1. 原问题的同义表述
2. 补充关键词的表述
3. 问题反方向的表述
以JSON数组格式输出。
""".formatted(query);
String response = chatClient.prompt().user(prompt).call().content();
return parseJsonArray(response);
}4.4 常见问题与解决方案
问题1:召回率不够,经常检索不到相关内容
原因分析:
文档切分粒度不合适,关键信息被切断
嵌入模型对某些表述不敏感
查询词与文档表述差异大
解决方案:
优化切分策略,使用语义切分或标题切分
尝试不同的嵌入模型
增加查询改写和查询扩展
使用混合检索(向量+关键词)
问题2:召回内容不相关,噪音太多
原因分析:
相似度阈值设置太高,召回太多无关内容
文档中有很多重复或通用内容
检索算法不够精准
解决方案:
设置合理的相似度阈值(如0.7以上)
清洗文档,去除噪音内容
使用重排序模型精排
按元数据过滤(如只检索特定类别)
问题3:复杂问题无法检索到完整答案
原因分析:
答案分散在多个文档片段
单次检索无法覆盖所有相关信息
问题涉及多个实体,需要追溯关联
解决方案:
使用多路查询,拆成多个子问题
增加检索次数上限
尝试Graph RAG,追溯实体关联
使用Agentic RAG,让智能体自主迭代检索
问题4:知识库更新不及时
原因分析:
文档更新后没有及时向量化
增量更新机制缺失
多版本文档混淆
解决方案:
设计增量更新流程,自动监测文档变化
每个文档带版本和时间元数据
检索时按时间过滤,优先返回最新版本
定期全量重建知识库(如每周)
五、Spring AI Alibaba集成RAG实战
5.1 环境搭建
依赖配置:
<dependencies>
<!-- Spring AI Alibaba核心 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M2</version>
</dependency>
<!-- 向量存储(Redis) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-vector-store</artifactId>
</dependency>
<!-- 文档处理 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
</dependencies>配置文件:
spring:
ai:
alibaba:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
chat:
options:
model: qwen-plus
embedding:
options:
model: text-embedding-v2
vectorstore:
redis:
uri: redis://localhost:6379
index: knowledge-base5.2 文档导入服务
@Service
public class KnowledgeImportService {
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
private final DocumentReaderFactory readerFactory;
public void importDocuments(String directory) {
List<Resource> resources = loadResources(directory);
for (Resource resource : resources) {
// 1. 根据文件类型选择Reader
DocumentReader reader = readerFactory.getReader(resource);
// 2. 读取文档
List<Document> rawDocs = reader.read(resource);
// 3. 清洗文档
List<Document> cleanedDocs = cleanDocuments(rawDocs);
// 4. 切分文档
List<Document> chunks = splitDocuments(cleanedDocs);
// 5. 添加元数据
List<Document> enrichedChunks = enrichMetadata(chunks, resource);
// 6. 向量化并存储
vectorStore.add(enrichedChunks);
log.info("导入完成: {} 个片段", enrichedChunks.size());
}
}
private List<Document> splitDocuments(List<Document> docs) {
// 使用TokenTextSplitter,带重叠
TokenTextSplitter splitter = new TokenTextSplitter(
500, // 默认片段大小
50, // 重叠大小
5, // 最小片段大小
10000, // 最大片段大小
true // 保持段落完整性
);
return splitter.split(docs);
}
private List<Document> enrichMetadata(List<Document> chunks, Resource source) {
String filename = source.getFilename();
String importTime = LocalDateTime.now().toString();
return chunks.stream()
.map(chunk -> new Document(
chunk.getContent(),
Map.of(
"source", filename,
"imported_at", importTime,
"chunk_id", UUID.randomUUID().toString()
)
))
.toList();
}
}5.3 RAG问答服务
基础RAG实现:
@Service
public class BasicRAGService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
public BasicRAGService(ChatClient.Builder builder, VectorStore vectorStore) {
this.vectorStore = vectorStore;
this.chatClient = builder
.defaultSystem("""
你是知识库问答助手。
请根据提供的上下文回答用户问题。
如果上下文中没有相关信息,请明确说不知道,不要编造。
回答时请标注信息来源。
""")
.build();
}
public String query(String question) {
// 1. 检索相关文档
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.query(question)
.withTopK(5)
.withSimilarityThreshold(0.7)
);
if (docs.isEmpty()) {
return "抱歉,知识库中没有找到相关信息。";
}
// 2. 拼接上下文
String context = docs.stream()
.map(doc -> """
【来源:%s】
%s
""".formatted(doc.getMetadata().get("source"), doc.getContent()))
.join("\n---\n");
// 3. 构建提示
String prompt = """
上下文信息:
%s
用户问题:%s
请基于上下文回答问题,并标注信息来源。
""".formatted(context, question);
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}使用Advisor自动注入RAG:
Spring AI提供了QuestionAnswerAdvisor,自动处理检索和注入:
@Service
public class AdvisorRAGService {
private final ChatClient chatClient;
public AdvisorRAGService(ChatClient.Builder builder, VectorStore vectorStore) {
this.chatClient = builder
.defaultSystem("""
你是知识库问答助手。
请根据系统提供的检索结果回答问题。
如果检索结果中没有相关信息,请明确说不知道。
""")
.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore))
.build();
}
public String query(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}Advisor会自动:
将用户问题向量化
检索向量存储
将检索结果注入到提示中
模型基于增强后的提示生成答案
5.4 高级RAG实现
混合检索:
@Service
public class HybridRAGService {
private final VectorStore vectorStore;
private final KeywordSearchIndex keywordIndex;
private final ChatClient chatClient;
private final CrossEncoderReranker reranker;
public String query(String question) {
// 1. 向量检索
List<Document> vectorResults = vectorStore.similaritySearch(
SearchRequest.query(question).withTopK(10)
);
// 2. 关键词检索
List<Document> keywordResults = keywordIndex.search(question, 10);
// 3. 融合排序
List<Document> fusedResults = reciprocalRankFusion(vectorResults, keywordResults);
// 4. 重排序
List<Document> rerankedResults = reranker.rerank(question, fusedResults, 5);
// 5. 生成答案
String context = buildContext(rerankedResults);
return generateAnswer(question, context);
}
private List<Document> reciprocalRankFusion(
List<Document> vectorDocs, List<Document> keywordDocs
) {
Map<String, Double> scoreMap = new HashMap<>();
int k = 60; // RRF常数
// 向量检索得分
for (int i = 0; i < vectorDocs.size(); i++) {
String id = vectorDocs.get(i).getMetadata().get("chunk_id");
scoreMap.merge(id, 1.0 / (k + i + 1), Double::sum);
}
// 关键词检索得分
for (int i = 0; i < keywordDocs.size(); i++) {
String id = keywordDocs.get(i).getMetadata().get("chunk_id");
scoreMap.merge(id, 1.0 / (k + i + 1), Double::sum);
}
// 合并并排序
return scoreMap.entrySet()
.stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.map(e -> findDocumentById(e.getKey(), vectorDocs, keywordDocs))
.filter(Objects::nonNull)
.limit(10)
.toList();
}
}查询改写与多路查询:
@Service
public class QueryOptimizationService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
public List<Document> optimizedSearch(String originalQuery) {
// 1. 查询改写
String rewrittenQuery = rewriteQuery(originalQuery);
// 2. 生成多个查询变体
List<String> queries = generateQueryVariants(originalQuery);
queries.add(rewrittenQuery);
// 3. 多路检索
List<Document> allResults = new ArrayList<>();
for (String query : queries) {
List<Document> results = vectorStore.similaritySearch(
SearchRequest.query(query).withTopK(5)
);
allResults.addAll(results);
}
// 4. 去重并重排
return deduplicateAndRerank(originalQuery, allResults);
}
private String rewriteQuery(String query) {
String prompt = """
请将以下问题改写为更适合检索的形式。
要求:
1. 补充可能缺失的关键词
2. 使用更标准的表述
3. 不要改变问题的核心含义
原问题:%s
直接输出改写结果。
""".formatted(query);
return chatClient.prompt().user(prompt).call().content();
}
private List<String> generateQueryVariants(String query) {
String prompt = """
请为以下问题生成3个不同的检索查询变体。
要求:
1. 使用不同的表述方式
2. 补充不同的关键词角度
3. 保持问题核心不变
原问题:%s
以JSON数组格式输出,例如:["变体1", "变体2", "变体3"]
""".formatted(query);
String response = chatClient.prompt().user(prompt).call().content();
return parseJsonArray(response);
}
}5.5 Agentic RAG实现
智能体自主检索:
@Service
public class AgenticRAGAssistant {
private final ChatClient chatClient;
private final VectorStore vectorStore;
private final KeywordSearchIndex keywordIndex;
private final DatabaseQueryTool dbTool;
private final ApiQueryTool apiTool;
public AgenticRAGAssistant(ChatClient.Builder builder,
VectorStore vectorStore,
KeywordSearchIndex keywordIndex,
DatabaseQueryTool dbTool,
ApiQueryTool apiTool) {
this.vectorStore = vectorStore;
this.keywordIndex = keywordIndex;
this.dbTool = dbTool;
this.apiTool = apiTool;
this.chatClient = builder
.defaultSystem("""
你是智能问答助手,具备多种信息获取能力。
回答问题时请遵循以下流程:
1. 分析问题类型:
- 知识库问题:检索知识库文档
- 实时数据问题:调用API获取最新数据
- 数据库查询问题:查询数据库
- 计算分析问题:调用计算工具
2. 选择合适的检索或查询方式:
- 语义问题:使用vector_search
- 精确匹配问题:使用keyword_search
- 复杂问题:多次检索或混合检索
3. 评估检索结果:
- 如果信息不完整,改写查询重新检索
- 如果需要补充数据,调用其他工具
4. 整合信息生成答案:
- 标注信息来源
- 如果信息不足,明确说明
可用工具:
- vector_search: 向量检索知识库
- keyword_search: 关键词检索
- database_query: 数据库查询
- api_query: 外部API查询
- evaluate_results: 评估检索结果是否充分
""")
.defaultFunctions(
new VectorSearchTool(vectorStore),
new KeywordSearchTool(keywordIndex),
dbTool,
apiTool,
new ResultEvaluatorTool()
)
.build();
}
public String query(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
public Flux<String> queryStream(String question) {
return chatClient.prompt()
.user(question)
.stream()
.content();
}
}
// 检索工具定义
@Component
public class VectorSearchTool {
private final VectorStore vectorStore;
@Tool(description = "向量检索知识库,适合语义匹配的问题")
public List<SearchResult> vectorSearch(
@ToolParam(description = "查询内容") String query,
@ToolParam(description = "返回结果数量,默认5") int topK
) {
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.query(query).withTopK(topK)
);
return docs.stream()
.map(doc -> SearchResult.builder()
.content(doc.getContent())
.source(doc.getMetadata().get("source"))
.score(doc.getMetadata().get("similarity"))
.build())
.toList();
}
}
@Component
public class ResultEvaluatorTool {
@Tool(description = "评估检索结果是否充分,判断是否需要继续检索")
public EvaluationResult evaluateResults(
@ToolParam(description = "用户原始问题") String query,
@ToolParam(description = "当前检索到的内容摘要") String retrievedContent
) {
String prompt = """
用户问题:%s
当前检索内容:%s
请评估:
1. 检索内容是否足以回答问题?(是/否)
2. 缺少哪些关键信息?
3. 建议的下一步操作(继续检索/改写查询/调用其他工具/已充分)
以JSON格式输出。
""".formatted(query, retrievedContent);
// 这里可以用另一个模型调用来评估
// 实际项目中可能直接让主智能体自己判断
return EvaluationResult.parse(prompt);
}
}5.6 完整API接口
@RestController
@RequestMapping("/api/rag")
public class RAGController {
private final AgenticRAGAssistant assistant;
private final KnowledgeImportService importService;
@PostMapping("/query")
public ResponseEntity<RAGResponse> query(@RequestBody RAGRequest request) {
String answer = assistant.query(request.getQuestion());
return ResponseEntity.ok(RAGResponse.builder()
.answer(answer)
.timestamp(LocalDateTime.now())
.build());
}
@PostMapping("/query/stream")
public Flux<String> queryStream(@RequestBody RAGRequest request) {
return assistant.queryStream(request.getQuestion());
}
@PostMapping("/import")
public ResponseEntity<ImportResponse> importDocuments(
@RequestParam("directory") String directory
) {
importService.importDocuments(directory);
return ResponseEntity.ok(ImportResponse.builder()
.status("success")
.message("文档导入完成")
.build());
}
}六、RAG效果评估与优化
6.1 评估指标
RAG效果需要定量评估,不是"感觉还行"就够了:
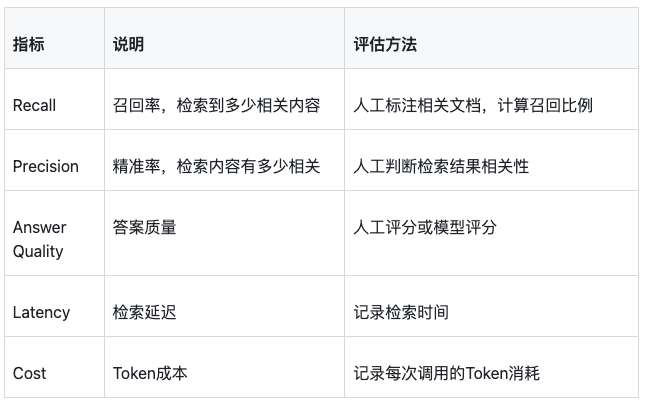
6.2 评估流程
@Service
public class RAGEvaluationService {
private final VectorStore vectorStore;
private final ChatClient evaluatorClient;
public EvaluationReport evaluate(List<TestQuestion> testQuestions) {
List<EvaluationResult> results = new ArrayList<>();
for (TestQuestion question : testQuestions) {
// 执行检索
List<Document> retrieved = vectorStore.similaritySearch(
SearchRequest.query(question.getQuery()).withTopK(5)
);
// 计算召回率(如果有标注的正确答案文档)
double recall = calculateRecall(retrieved, question.getExpectedDocs());
// 生成答案
String answer = generateAnswer(question.getQuery(), retrieved);
// 评估答案质量
double answerScore = evaluateAnswerQuality(
question.getQuery(), answer, question.getExpectedAnswer()
);
results.add(EvaluationResult.builder()
.query(question.getQuery())
.recall(recall)
.answerScore(answerScore)
.build());
}
return EvaluationReport.builder()
.avgRecall(results.stream().mapToDouble(EvaluationResult::getRecall).average())
.avgAnswerScore(results.stream().mapToDouble(EvaluationResult::getAnswerScore).average())
.build();
}
private double evaluateAnswerQuality(String query, String answer, String expected) {
String prompt = """
请评估以下答案的质量。
问题:%s
实际答案:%s
期望答案:%s
评估维度:
1. 准确性(0-10)
2. 完整性(0-10)
3. 可读性(0-10)
以JSON格式输出评分。
""".formatted(query, answer, expected);
String evaluation = evaluatorClient.prompt().user(prompt).call().content();
return parseScore(evaluation);
}
}6.3 持续优化循环
RAG上线后要持续优化:
收集反馈 → 分析问题 → 优化文档/检索 → 重新评估 → 上线收集反馈的方式:
用户评分(答案是否有帮助)
用户追问(如果追问多,说明答案不完整)
问题分析(哪些问题检索效果差)
优化方向:
补充缺失的文档内容
优化文档切分策略
调整检索参数(topK、阈值)
增加查询改写规则
引入重排序模型
七、常见问题
Q1:RAG和微调应该选哪个?
简单问答场景用RAG就够了。需要深度内化知识、改变模型行为习惯的场景考虑微调。两者可以结合:微调改能力,RAG补知识。
Q2:文档切分应该怎么设置?
避免固定长度切分,推荐语义切分或按标题切分。片段大小500-1000Token比较合适,相邻片段要有重叠(50-100Token)防止切断关键信息。
Q3:向量检索效果不好怎么办?
尝试混合检索(向量+关键词)、增加查询改写、使用重排序模型。检查嵌入模型是否适合你的语言和领域。
Q4:Graph RAG什么时候用?
问题涉及多个实体、需要追溯关系链、需要综合多篇文档时考虑Graph RAG。简单问答不需要,成本高实现复杂。
Q5:Agentic RAG成本高吗?
是的,每次决策都要调用模型。但检索效率更高,不是每次都检索,整体可能反而节省成本。适合复杂问题场景。
Q6:如何处理知识库更新?
设计增量更新机制,监测文档变化自动更新向量。关键文档优先更新,非关键文档定期批量更新。每次检索按时间过滤,优先返回最新内容。
八、总结
RAG是目前让大模型"知道"企业私有数据最务实的技术方案。从基础的Naive RAG到高级的Graph RAG、Agentic RAG,不同形态适应不同场景。
核心要点:
文档处理是基础 —— 切分策略、清洗质量直接决定检索效果。不要忽视这个环节。
检索优化是关键 —— 混合检索、重排序、查询改写,这些优化能大幅提升召回精准度。
形态选择要务实 —— 不是所有场景都需要Graph RAG或Agentic RAG。简单问题用简单方案,复杂问题用复杂方案。
持续迭代是常态 —— RAG上线后要持续收集反馈、评估效果、优化调整。不是一劳永逸的。
Spring AI Alibaba提供了完整的RAG能力支持,从文档处理、向量化、检索到智能体编排都有现成的组件。结合本文介绍的理论和最佳实践,可以在实际项目中高效落地RAG。
参考资料: